
RAG 요약
RAG란 (Retrieval-Augmented Generation = 검색 증강 생성) 이란 뜻으로, 언어모델이 특정 데이터를 검색하여 답변을 생성하는 방식을 말합니다.
RAG의 장점
AI Model 자체 성능에 모든걸 의존하는건 비효율적이고 사실상 AI 자체 메모리(학습내용)가 커지면 커질수록 연산량은 기하급수적으로 증가하기때문에, 모델성능은 필요한 언어를 잘 이해하고 요약이나 생성 할수 있을정도면 충분하고, 답변을 생성할때 필요한 지식부분은 별도의 DATA에 의존하게 함으로써 모델의 성능(속도 퍼포먼스 측면)을 취할수있고 연산량도 최적화시킬수있고, 데이터의 정확성도 높일수있는 즉, 언어모델이 효율적으로 작동하게 할수있는 기법이라고 볼수있음.
Fine-Tuning 과 차이점
Fine-Tuinng은 사전 학습모델을 살짝 변형시키는 구조로, 어떤 기능추가라거나 모델이 참고할 데이터(지식)를 추가해주는것이 가능하지만, 해당 데이터나 기능추가부분이 가중치의 일부로 흡수되는 방식이여서 RAG방식보다 새로운 데이터에 대한 명확성이 떨어질 수 있음.
정리하면..
graph TD; A[Pretrained Model] B[Fine Tuning] C[RAG]
- Pretrained Model(사전학습모델): 언어를 당담. 여러가지 언어를(용도에 필요한) 이해하고 번역이가능하고, 뜻을이해해서 유사문장을 가려낼수있고, 특정 의미를 담는 문장을 생성할수있음.
- Fine Tuning(전이 학습): 사전학습모델이 특정 기능을 더 잘 할수있도록 업데이트함. (optional, 사전학습모델이 원하는기능을 할수 없을때만 하면 됨)
- RAG(검색 증강 생성): 언어모델이 미리 구축된 DATABASE에서 쿼리를통해 필요한 정보를 검색해서 답변을 생성하는 방법.
요약하면 RAG를 적용할경우 언어모델은 지능 역할을 하고, RAG에서 사용되는 데이터는 지식의 역할을함.
여기서 또 고려해야 하는점은 사전학습모델은 지능의 역할을 하는데, 학습방법이 지식을 통해서 지능을 높이기때문에 일정 지능을 갖추려면 지식도 많이 알려줘야 한다는점
RAG 데이터는 지식 역할을 한다지만, 데이터가 RAW 데이터로 다 저장되기때문에 저장 용량을 많이 차지함.
모델의 지능이 낮으면 RAG의 데이터를 활용할수없고 RAG데이터가 너무많아지면 가중치용량보다 더커질수있어서 밸런스를 맞추는게 필요함.
기본 RAG 아키텍쳐
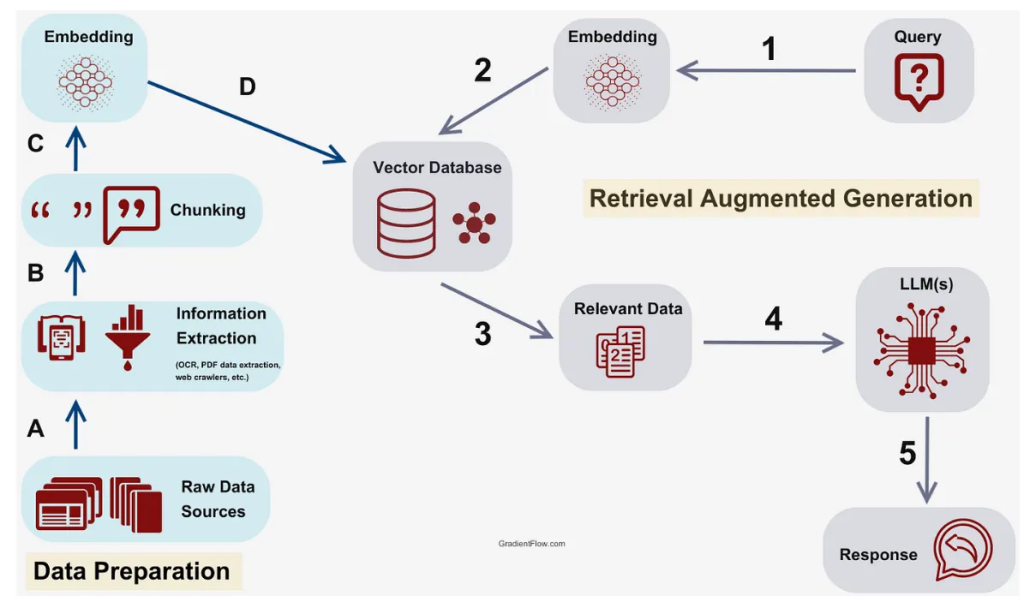
RAG 역사
- Naive RAG: 위 그림같은 구조로 검색하여 찾은 데이터를 제공함.
- Advanced RAG: 더 잘 검색하고, 필터링한 후, 정리해서 제공한다.
- Modular RAG: 검색, 판단, 도구, 재검색, 검증 을 레고처럼 조립힌다.
- Graph RAG: GraphRAG는 문서를 단순 chunk 목록으로 보지 않고, entity와 relationship 중심의 graph로 바꿔서 검색·요약하는 방식입니다. Microsoft Research는 GraphRAG를 텍스트 추출, 네트워크 분석, LLM prompting/summarization을 결합한 end-to-end 시스템으로 설명합니다.
- Self-RAG: 모델이 언제 검색할지, 검색 결과를 사용할지, 답변이 근거에 맞는지를 스스로 판단하게 만드는 방향입니다.
- CRAG (Corrective RAG): CRAG는 검색 결과가 나쁠 때 교정 행동을 넣는 방식입니다. 검색된 문서의 품질을 평가하는 lightweight retrieval evaluator를 두고, confidence에 따라 다른 retrieval action을 실행합니다
- RAPTOR:
- Contextual Retrival:
- Late Chunking:
- RAFT:
- Agentic RAG:
4번~11번은 최신 변화중인 RAG 기법들
1. Naive RAG (구현 쉬움, 검색결과가 안좋으면 답변 퀄리티도 안좋음)
사용자가 “회사 휴가 규정 알려줘” 라고 물으면 벡터 DB에서 휴가 관련 chunk를 몇개 가져와서 LLM에게 같이 넣어주는 방식.
문서 준비
→ chunk 분할
→ embedding
→ vector DB 저장
→ 사용자 질문 embedding
→ 유사 chunk 검색 top-k
→ LLM에게 context로 넣기
→ 답변 생성검색 결과를 그대로 제공하기때문에, 관련 있어 보이지만, 실제로는 도움이 안되는 답변일 경우가 많음.
2. Advanced RAG
Naive RAG과 유사하지만, 검색 전후에 여러 개선 단계를 추가함
| 기법 | 설명 |
|---|---|
| Hybrid Search | 벡터 검색 + BM25 키워드 검색을 같이 사용 |
| Reranking | 검색된 20~50개 문서 중 진짜 관련 높은 것만 다시 정렬 |
| Query Rewrite | 사용자의 질문을 검색하기 좋은 형태로 재작성 |
| Multi-query Retrieval | 질문을 여러 버전으로 바꿔서 검색 |
| Query Decomposition | 복잡한 질문을 작은 질문 여러 개로 분해 |
| Context Compression | 검색된 문서에서 답변에 필요한 부분만 압축 |
| Metadata Filtering | 날짜, 카테고리, 작성자, 문서 타입 등으로 필터링 |
| Parent-child Chunking | 작은 chunk로 검색하고, 실제 context는 더 큰 parent 문단을 사용 |
예를 들어 “2023년과 2024년 매출 차이와 원인을 알려줘”라는 질문은 한 번의 검색으로는 부족할 수 있습니다. Advanced RAG는 질문을 “2023년 매출”, “2024년 매출”, “매출 변화 원인”처럼 쪼개서 검색한 뒤, 결과를 합쳐 답하게 만들 수 있습니다.
장점
Naive RAG보다 훨씬 실무적입니다.
검색 실패율을 낮출 수 있습니다.
문서가 많아져도 어느 정도 대응 가능합니다.
회사 문서 검색, 기술문서 QA, 법률/계약서 분석 같은 곳에 적합합니다.
단점
구성이 복잡해집니다.
검색, reranking, LLM 호출이 늘어나 비용과 latency가 증가합니다.
잘못 설계하면 “복잡한데 성능은 별로 안 좋아지는” 상태가 됩니다.
3. Modular RAG
Modular RAG는 단순히 “Advanced RAG보다 더 고급”이라기보다는, RAG 시스템을 모듈 단위로 분해해서 필요에 따라 조립하는 구조입니다.
예를들면 이런식 입니다. 핵심은 질문에 따라 다른 경로를 선택한다는 것입니다.
Router
→ Query Analyzer
→ Retriever A: Vector DB
→ Retriever B: SQL DB
→ Retriever C: Web Search
→ Reranker
→ Verifier
→ Generator
→ Citation Checker| 질문 | 사용 모듈 |
|---|---|
| “이 문서 요약해줘” | 문서 chunk retrieval + summarizer |
| “지난달 매출 알려줘” | SQL query generator + DB lookup |
| “최근 뉴스까지 반영해줘” | web search + retriever |
| “계약서 위험 조항 찾아줘” | legal retriever + reranker + verifier |
| “전체 문서의 주요 테마 알려줘” | GraphRAG 또는 hierarchical summarization |
장점
확장성이 좋습니다.
문서 검색, DB 조회, API 호출, 웹 검색, 코드 실행 등을 하나의 RAG 시스템 안에 넣을 수 있습니다.
복잡한 업무 자동화에 적합합니다.
Agentic RAG와 결합하기 쉽습니다.
단점
설계 난도가 높습니다.
모듈 간 데이터 형식, 실패 처리, 비용 관리, 평가 시스템이 필요합니다.
작은 프로젝트에는 과할 수 있습니다.
- Chunking 전략
- Embedding 모델
- Vector Database -> Chroma DB Python 한 줄 설치, 디스크에 저장, 학습 프로토타입의 기본 선택
- Retriever ( Similarity Search vs MMR – Maximal Marginal Relevance )
Deep Dive
PDF 깨지지않게
- OCR
- PDF Parser
저장된 Chunk 는 json
Parent-child Chunking (계층구조)
Query Rewriting