
프로젝트 설명
개요: 허깅페이스에서 직접 모델을 다운받아 Fine-Tuning을 시키고, 그동안 배운 테크닉들을 활용하여 모델 성능 (accuracy)를 올린다.
주제는 자유주제로 말씀해주셨지만 2.5일 짧은 프로젝트 기간을 감안해 단순하고 방금전에 배워서 시작하기 쉬운 “언어만 한국어로 바뀐 두문장 관계” 분석을하는 모델로 fine-tuning 해볼생각이다. (두문장 관계 평가란 두 문장이 같은의미를 지닌 문장인지 평가하는것을 말한다.)
모델학습을 통해 성능을 올리는것이 목표지만, 더 중요한것은 성능을 올리기위해 어떤것을 해봤는지 경험하고 어떤차이가 있었는지 비교를통해 fine-tuning 할때 어떤방법으로 어느정도 개선을 했을때 어떤차이를 보이더라 하는 그런 감각을 체득하는것 등 이 더 중요하다고 생각한다. 따라서 가능하면 무언가 수정할때는, 꼭 평가를해보고 가능하면 실제로 문장을 집어 넣어 테스트를 해서 어떤지 비교도 해볼 생각이다.
성능 개선과 더불어 모델 학습속도를 늘려줄수있는 최적화 기법도 중요하다.
루브릭
- klue/bert-base를 NSMC 데이터셋으로 fine-tuning 하여, 모델이 정상적으로 작동하는 것을 확인하였다.
- Preprocessing을 개선하고, Validation accuracy를 90% 이상으로 개선하였다.
- Bucketing을 성공적으로 적용하고, 연산 속도와, 모델 성능간 trade-off 관계가 발생하는지 여부를 확인하였다.
프로젝트 구조
평가기준에 klue/bert-base를 NSMC 데이터셋으로 fine-tuning 하라고 되어있다, 루브릭 크게 신경쓰지 말라는 말씀도 계셨지만 아무튼 나는 한국어 두 문장 관계도를 파악하는 모델로 훈련할 생각이기 때문에, 상관이 없긴하다. (하지만 나중에 모델을 교체할수도 있긴하다)
기본 구조
graph LR; a[데이터 분석 및 HF Dataset] b[모델 및 tokenizer] c[데이터셋 전처리 및 모델 학습] d[FT로 모델 성능 향상] e[Bucketing으로 학습 결과분석] a-->b b-->c c-->d d-->e
고려 사항
프로젝트 할때는 어느정도 리서치를 하면서 머리에 정리를하면서 해보면 좋겠죠?
klue/bert-base 모델 사용시 mecab 사용금지.
리서치중 klue/bert-base는 학습될 때 형태소 분석기를 거치지 않고, 원본 텍스트를 바로 자체 토크나이저(WordPiece)로 쪼개어 학습되었습니다. 만약 억지로 Mecab으로 먼저 쪼갠 뒤 모델에 넣으면, 모델이 한 번도 본 적 없는 이상한 띄어쓰기와 토큰 조합이 입력되어 오히려 성능이 크게 떨어 진다는것을 알게되었음.
STEP 1. 데이터 분석 및 전처리 (EDA & Preprocessing)
- 중복 데이터 제거, pandas나 datasets의 기능을 이용해, 텍스트가 일치하는 중복 아이템 제거
- 정규식(Regex) 정제: *한글, 영문, 숫자, 기본 구두점만 남기고 의미없는 특수문자나 과도한 자음/모음 반복을 축소 (예: ㅋㅋ, ㅎㅎ 등 2개로 제한) 하는 전처리 적용.
- 최적의 max_length 찾기 (EDA 시각화):
- 리뷰 길의 분포를 히스토그램으로 그려보기. 보통 95%정도 데이터가 특정 길이에 들어옴. max_length를 무조건 크게잡으면 패딩 때문에 연산시간이 크게 나빠짐.
STEP 2&3. 토크나이저 및 학습 초기 설정
- Dynamic Padding (동적 패딩)
- DataCollatorWithPadding 을 사용하여 배치 내에서 가장 긴 문장을 기준으로만 패딩을 적용 (Step 5의 Bucketing과 결합을 하면 효과가 극대화)
STEP 4. 90% 이상을 위한 하이퍼 파라미터 최적화 (Fine-tuning)
- 학습률 스케줄러 변경: 기본값인
linear대신cosine_with_restarts또는cosine스케줄러를 사용해 보세요. 모델이 지역 최소점(Local Minima)에 빠지는 것을 방지해 줍니다. - Weight Decay 조정: 과적합(Overfitting)을 막기 위해
weight_decay값을 0.01에서 0.1 사이로 미세 조정해 보세요. - Early Stopping (조기 종료):
EarlyStoppingCallback을 적용하여 Validation Loss가 더 이상 안 떨어지면 학습을 멈추고 가장 좋았던 체크포인트로 복원하도록 설정하세요. - Optuna 융합 (고급): 하이퍼파라미터(Batch size, Learning rate 등)를 수동으로 찾기 힘들다면
Optuna라이브러리를 Hugging FaceTrainer에 연동하여 최적의 조합을 자동으로 찾게 만들 수 있습니다. - 평가함수 compute_metrics() 를 numpy로직접 구현하는것보다 최적화된 scikit-learn 활용하면 성능잇점이 있다고함 코드에 주석확인.
STEP 5. 성능 vs 훈련 시간 분석 및 고도의 시각화 (결과분석)
- Weights & Biases (W&B) 도입: *
pip install wandb를 설치하고TrainingArguments에report_to="wandb"를 추가해 보세요.- Bucketing을 켰을 때와 껐을 때의 Loss 하락 곡선, GPU 메모리 사용량, 학습 속도(Steps/sec)를 웹 대시보드에서 화려하고 직관적인 그래프로 겹쳐서 비교할 수 있습니다.
- Confusion Matrix (혼동 행렬) 시각화:
- 단순히 Accuracy 숫자만 내지 말고, Validation 세트의 예측 결과를 뽑아
scikit-learn과seaborn을 활용해 Confusion Matrix를 그려보세요. - “우리 모델은 긍정을 부정으로 착각하는 경우가 더 많을까? 아니면 부정을 긍정으로 착각하는 경우가 더 많을까?” 같은 깊이 있는 인사이트를 도출할 수 있습니다.
- 단순히 Accuracy 숫자만 내지 말고, Validation 세트의 예측 결과를 뽑아
- 오답 노트 (Error Analysis):
- 모델이 틀린 리뷰들만 따로 모아서 데이터프레임으로 출력해 보세요. “아, 비꼬는 반어법 리뷰(예: ‘참~~ 재밌네’)를 모델이 못 맞추는구나!” 같은 정성적인 분석이 가능합니다.
Projects Attempts
(1) 첫 번째 시도
첫번 째 시도는 튜토리얼에서 배운것을 한국어버전으로 만들기 위해 최소한의 수정만 거친 버전이다.
graph LR; a[1.데이터 분석 및 HF Dataset] b[2.모델 및 tokenizer] c[3.데이터셋 전처리 모델학습] d[4.FT로 모델 성능 향상] e[5.Bucketing 학습 결과분석] a-->b b-->c c-->d d-->e
(1)-1. EDA
한국어 두문장 관계 데이터셋인 KLUE-STS 사용
train/evaluation/test 데이터로 분리: train:10501, evaluation:1167, test:519 | test가 STS자체에서 제공한 validation split.
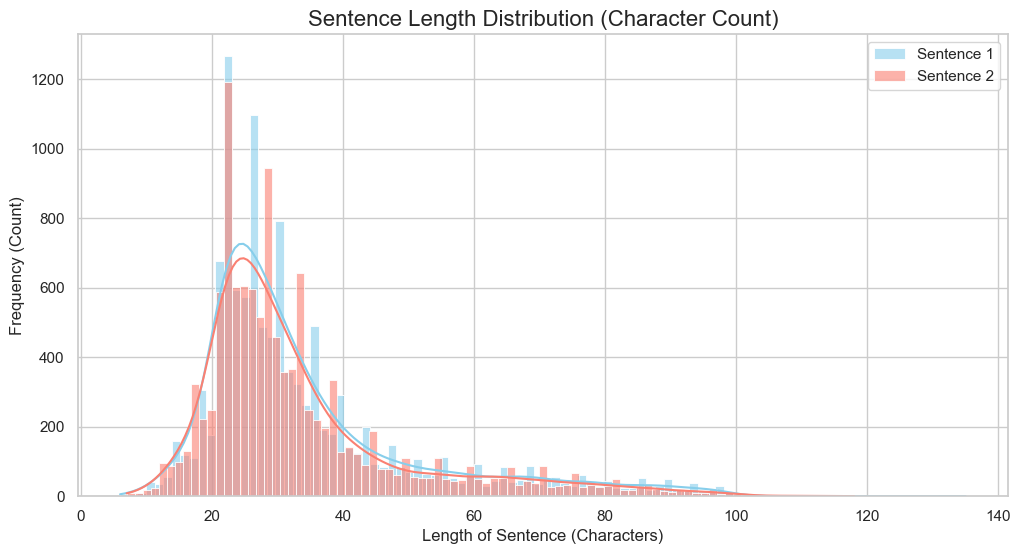
문자열 길이 분포도 확인. (추후 패딩용) 길이가120안에 다 들어가는것을 확인.
(1)-2&3. 토크나이저와 모델
라이브러리: transformer
언어 모델: klue/bert-base
토크나이저: transformer 내장 AutoTokenizer
패딩: 추후 동적패딩과 성능비교를 해보기위해 정적 패딩 사용. EDA에서 확인한 문자열길이를 기준으로 모든 데이터를 커버할수있는 MAX_LENGTH=128
패딩 데이터 직접확인, 레이블도 앞부분 14개 확인해봤는데 1개뺴고 다 맞다고 판단 (신뢰도 90%+)
첫시도 특별한 전처리는 없이 바로 실행
(1)-4. Train/Evaluation과 Test
best checkpoint는 f1 기준으로 선택.
소스코드
https://github.com/ohmanbo/AIFFEL_quest_eng/blob/main/LLM_Application/LLM04/HF_korean_project.ipynb
6. 결과
훈련시간: 196.7s
| Training Loss | Validation Loss | Epoch | Accuracy | Precision | Recall | F1 |
|---|---|---|---|---|---|---|
| 0.006817 | 0.855822 | 3 | 0.842004 | 0.751825 | 0.936364 | 0.834008 |
Validation Accuracy 83.0% < 90% (부적격)
(1) tiral + 동적패딩 적용결과
훈련시간: 126s
| Training Loss | Validation Loss | Epoch | Accuracy | Precision | Recall | F1 |
|---|---|---|---|---|---|---|
| 0.034485 | 0.947046 | 3 | 0.816956 | 0.719298 | 0.931818 | 0.811881 |
Validation Accuracy 81.7% < 90% (부적격)
훈련시간은 늘어나고 정확도는 줄어드는 상콤한 상황!
[최종 평가 지표]
정적 패딩 평가 결과:
{‘eval_loss’: 0.8487739562988281, ‘eval_accuracy’: 0.8304431599229287, ‘eval_precision’: 0.7408759124087592, ‘eval_recall’: 0.9227272727272727, ‘eval_f1’: 0.8218623481781376}
버키팅 동적 패딩 평가 결과:
{‘eval_loss’: 0.9469589591026306, ‘eval_accuracy’: 0.8169556840077071, ‘eval_precision’: 0.7192982456140351, ‘eval_recall’: 0.9318181818181818, ‘eval_f1’: 0.8118811881188119}
확실히 동적패딩이 학습 속도는 눈에띄게 빨라지지만, 정확도는 낮은 문제가 발생 (trade-off 확인)
2번째 시도 – 학습을 위한 전략
A. STS 데이터셋에 label (True or False) 말고, real-label이라고 회귀값이 존재하는데 이걸기준으로 threadhold 조정해서 positive , negative 비율 postive가 좀더 많이 나오도록 조절하기.
KLUE-STS 점수 회귀 학습 후 threshold로 이진화하는 방식이 더 유력함
- 현재: 문장쌍 -> positive/negative
- 변경: 문장쌍 -> 유사도 점수 -> threshold로 positive/negative
B. 학습데이터가 크지않으니 evaluation으로 빼놨던 나머지 10%도 Train에 사용하기
C. epoch를 3회돌렸는데 10회만 돌리기.
D. 정적패딩 사용하기. 동적패딩이랑 속도차이가 몇배나는게아니고 30%정도만 빨라져서 그정도면 모델 성능을 위해 희생할만한 학습시간이라고 생각됨. 동적패딩 아예 코드도 넣지말기.
E. Learning rate를 2e-5 에서 2e-5 부터 5e-5 4단계로 시도해보고 가장좋은값 사용.
F. batch size 16으로 수정
G. 모델변경 klue/roberta-base
H. wandb.init 에서 name을 2nd trial로 수정
소스코드
학습결과
lr=2e-05 accuracy=0.9383 f1=0.9498 threshold=2.25 pred_positive_ratio=0.6185 time=708.07s
lr=3e-05 accuracy=0.9461 f1=0.9560 threshold=2.35 pred_positive_ratio=0.6146 time=788.65s
lr=4e-05 accuracy=0.9383 f1=0.9511 threshold=2.15 pred_positive_ratio=0.6493 time=540.65s
lr=5e-05 accuracy=0.9345 f1=0.9459 threshold=2.45 pred_positive_ratio=0.5992 time=557.46s
선택된 learning rate: 3e-05
선택된 prediction threshold: 2.35
선택된 모델 경로: transformers_klue_sts_regression_roberta_lr_3em05\best_model
테스트셋 결과
{‘eval_loss’: 0.33285850286483765, ‘eval_mse’: 0.3327992324688497, ‘eval_mae’: 0.4282605896357569, ‘eval_accuracy’: 0.9460500963391136, ‘eval_precision’: 0.9529780564263323, ‘eval_recall’: 0.9589905362776026, ‘eval_f1’: 0.9559748427672956, ‘eval_pred_positive_ratio’: 0.6146435452793835}
직접 작성한 예문 테스트
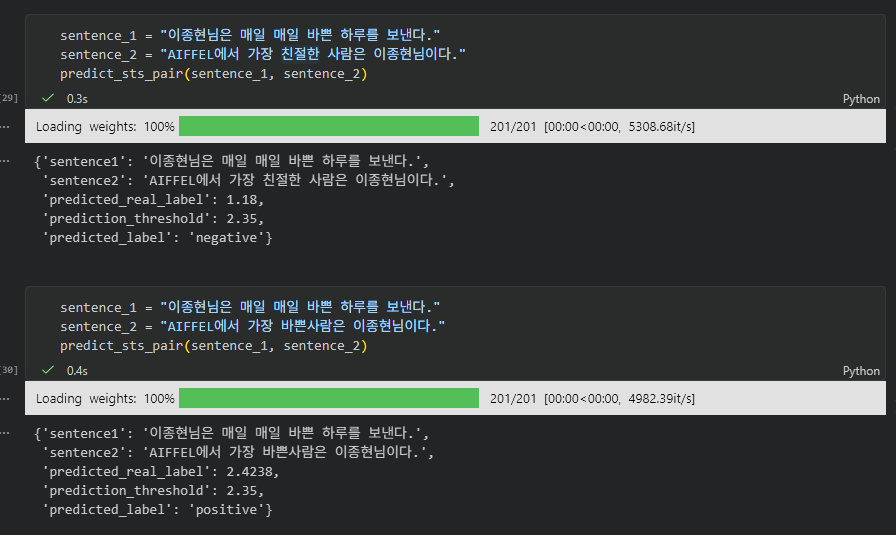
1) 바쁘다 -> 친절하다 로 바뀌면 유사도가 낮아서 negative -> 의도한 대로 작동 GOOD
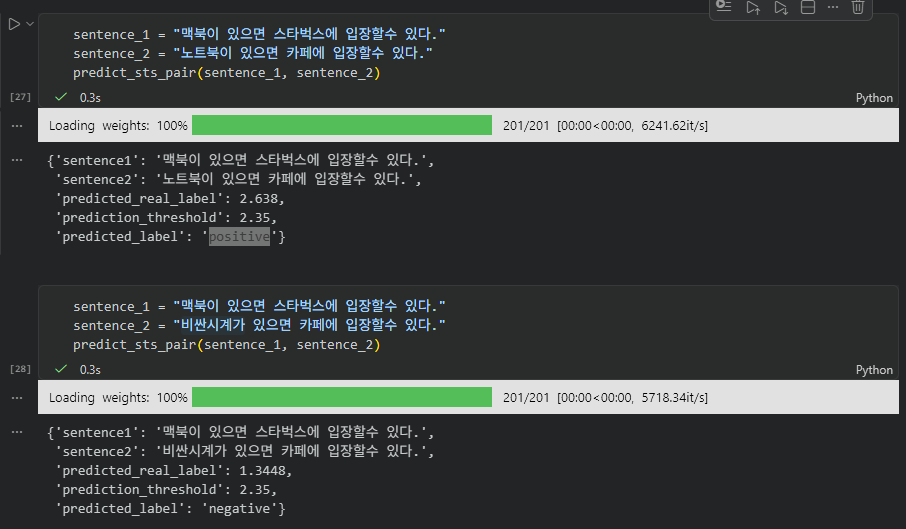
2) (맥북, 스타벅스) -> (노트북, 카페) 유사도 높음
and
(맥북, 스타벅스) -> (비싼시계, 카페) 유사도 낮음 -> 의도한 대로 작동 GOOD
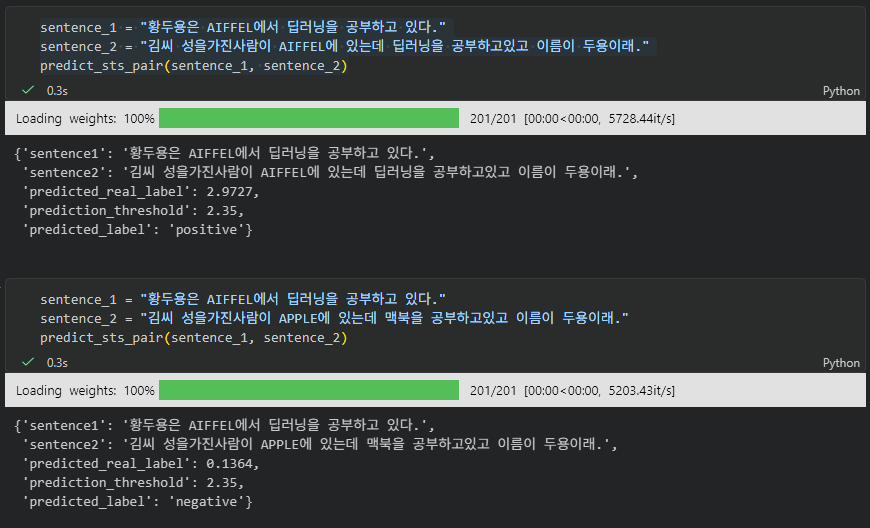
3) 이건 예시가 좀 많이 바뀌어서 직관적이지 않은데, (AIFFEL 딥러닝) -> (APPLE, 맥북) 유사도낮음.
3번째 (generate paraphrased sentences)
우선 두번째 학습결과가 지표로보나 실제 테스트결과로보나 너무 잘나와서 더 진행하지않아도 될것같다. 무얼 해볼까 계속 고민하던중 유사문장을 구분하는게아닌 유사문장을 만들어주는 기능을 만들어보면 어떨까 싶어서 decoder모델을 fine-tuning하기로 정했다.
모델은 Qwen3.5-4B로 정했는데 추론성능만 생각하고 너무 쉽게 정한게 아닌가싶다 ㅠㅠ 학습시키는데 1epoch에 3시간이 넘게 소요된다. 이런이유로 아직 결과가 나오지않아서 프로젝트 제출은 2번째로 제출하였다.
소스코드
커널 재시작후 저장된 모델, lora 파일들을 불러와서 다시 실행할수있도록 만든 standalone 버전 (모델은 용량때문에 못올림)
프로젝트 구성 (기존방법에서 바뀐부분)
- KLUE-STS 로드 (1~2번째에서 학습에 사용한 동일한 데이터)
- real-label >= 4.0 데이터만 paraphrase pair로 변환
- Qwen3.5-4B LoRA/QLoRA SFT
- 입력 문장으로 후보 30개 생성
- 기존 STS regression 모델로 후보 점수 계산
- top 10 정렬 출력
구성을 보면 알겠지만, 학습한모델로 유사문장을 30개 생성후 top10를 출력해주는 프로젝트이다 아직 학습중인데 결과가 어떤지에따라 추가계획을 생각해볼생각.
학습결과
학습시간 20314초 = 약 5시간 40분 (너무 오래걸려서 2epoch만 돌림)
| Epoch | Training Loss | Validation Loss |
|---|---|---|
| 1 | 1.013295 | 1.159228 |
| 2 | 0.723310 | 1.156065 |
테스트 1
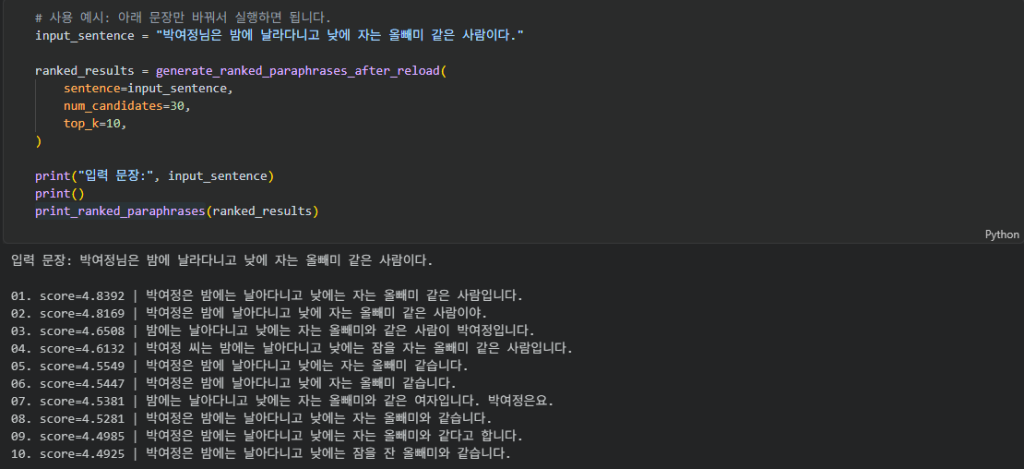
꽤 자연스스럽게 새로운 문장을 만들어내고, 07번째를 보면, 여자라고 입력하지않았는데도 여자라고 유추를 한건지 아무튼 그렇습니다.
테스트 2
다음에는 복잡한 문장을 해봤는데요
- 이건 대단한 기술이다
- 폴란드에는 이미수출했고, 여러나라에서 사고싶어 한다.
- 그 기술은 대한민국 방산 기술이다.
라는 2개의 단순문장과 1개의 복잡한문장 총 3개를 사용해서 모델이 어떻게 paraphrase하는지 확인해보았더니,
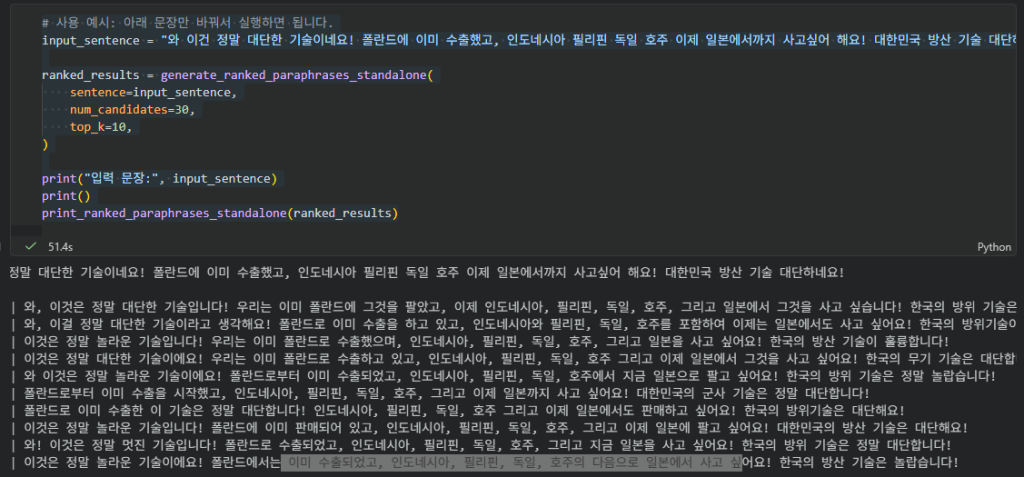
그럴듯 하지만, 대부분 맞지만 여러개의 오류도 쉽게 찾을수 있었습니다. 아무래도 학습한 예문이 복잡한문장이 많이 없어서 그런것 같습니다. 이런걸 개선하려면 더 복잡한 문장 또는 문단단위로 학습을하면 좋아질수도 있지않을까 생각해봅니다.
테스트 3
다시 복잡한 문장 1개만 가지고 해보았더니 정말 자연스럽게 다시 만들어주는걸 확인할 수 있었습니다.
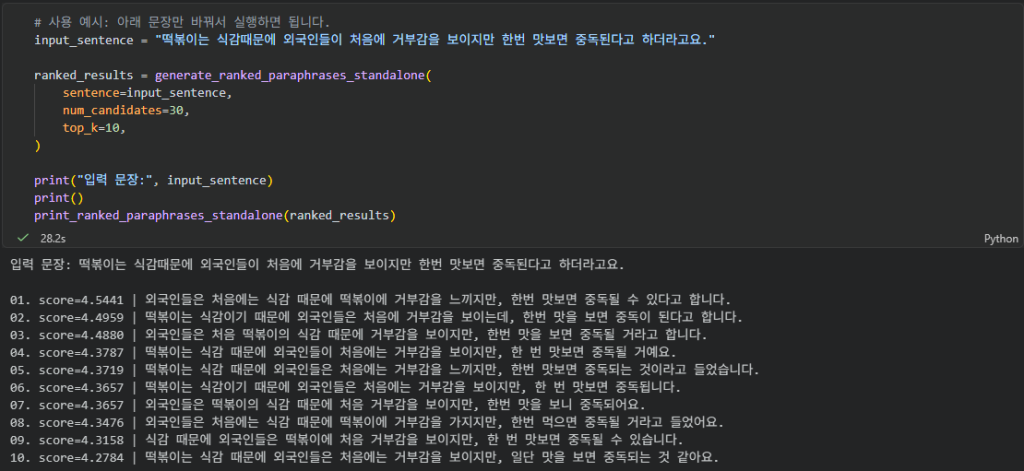
테스트 4
혹시 모델 자체가 성능이 좋아서 그런게 아닐까? 해서 영어문장도 테스트해보았는데,
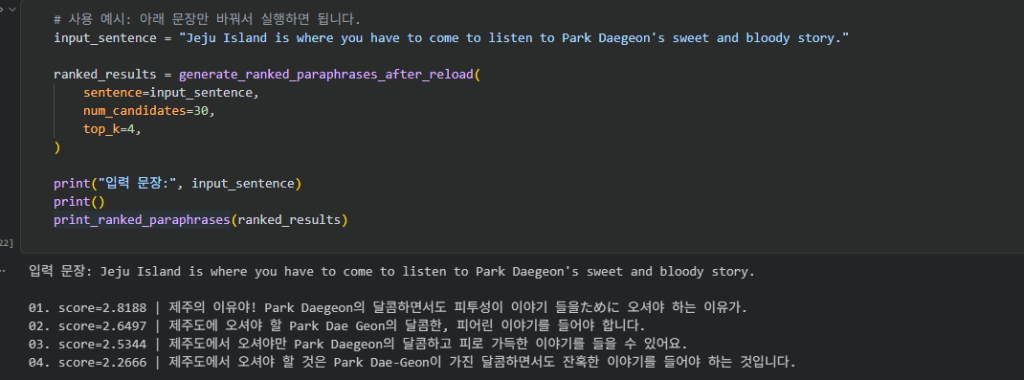
영어문장은 자연스럽지 않고, 한국어로 번역을 하려고하는걸봐서 확실히 모델도 좋지만, fine-tuning 영향이 적지않다는걸 느꼇습니다. 애초에 qwen 한국어보다 영어를 더 잘하는데 이런결과가 나온걸 보면요.