
용어정리
PyTorch – GPU 가속 가능한 강력한 텐서 연산과, 동적 계산 그래프나 자동미분을 지원하는 딥러닝 프레임워크.
- 동적 계산 그래프(DCG, Dynamic Computational Graph 중요특징): 코드를 실행하는 시점에 그래프가 생성되는 ‘define-by-run’ 방식. Python의 제어문(if, for)을 쓰듯 모델을 작성할수 있고 디버깅이 쉬움.
- 자동미분 (Autograd): 머신러닝의 핵심은 역전파(Backpropagation)인데, PyTorch는 연산에 대해 미분 값을 자동으로 계산해 준다.
- Pythonic: NumPy와 유사한 문법을 가지고있어 친숙하고 가독성이 뛰어남.
Tensor(텐서) – n차원 배열을 수학적으로 나타낸 기본 단위. 머신러닝에서는 PyTorch가 지원하는 기능 즉 GPU 가속연산을 지원하고 자동미분 정보를 포함하는 핵심 객체.
단일 가설(Hypothesis, h) – 데이터의 입력(x)과 출력(y) 사이의 함수를 의미한다. (X*W+b 같은 함수)
가설 집합(Hypothesis Set) – 모델이 가질 수 있는 모든 가능한 가설 후보들.
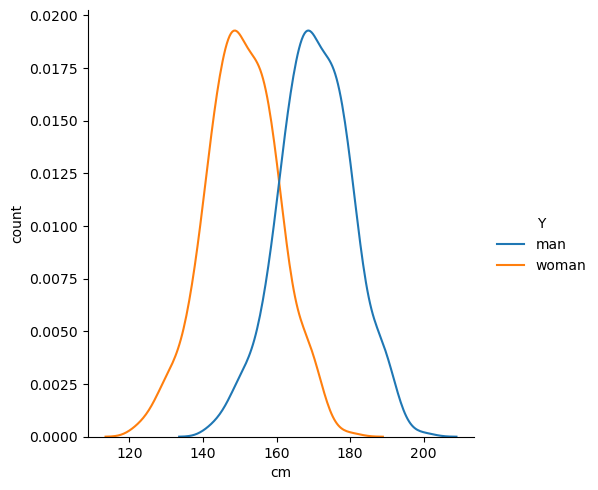
통계량(statistics, T-value): 아래 남녀 키차이 분포도 예시에서 T값이 31.96이 나왔다면, 두 그룹의 평균 차이가 표준 오차(noise크기)에 비해 약 32배나 크다는 뜻.
유의 확률(p-value): 데이터가 우연히 이렇게 뽑혔을 확률. 6.2285854381989205e-155는 $0.000…$ (0이 154개) 뒤에 6이 나오는 소수입니다. 즉, 남녀의 키차이가 없는데, 우연히 이런 데이터가 뽑혔을 확률이 0%에 가깝다는 이야기 입니다. (즉, 낮을수록 신뢰도 높은 데이터)
statistic, pvalue = stats.ttest_ind(man_height, woman_height, equal_var=True)
print("statistic:", statistic)
print("pvalue :", pvalue)
print("*:", pvalue < 0.05)
print("**:", pvalue < 0.001)statistic: 31.96162891312776 pvalue : 6.2285854381989205e-155 *: True **: True
손실 함수(Loss Function): 실제 값(검증 데이터의, y)과, 예측 값(prediction)에 차이가 발생했을때 오차가 얼마인지 계산하는 함수. MSE, MAE, RMSE, Huber Loss 등이 있다. 손실 함수는 목적 함수(Objective Function) 비용 함수(Cost Function) 라고 부르기도 한다.
교차 엔트로피(Cross-Entropy): 두 확률 분포가 얼마나 다른지를 측정하는 도구. 머신러닝 분류 문제에서 모델의 출력은 보통 “이 데이터가 각 클래스에 속할 확률(예: 개일 확률 80%, 고양이일 확률 20%)”로 나옵니다. 이때 모델이 예측한 확률 분포와 실제 정답의 확률 분포(개 100%, 고양이 0%) 사이의 거리를 계산하는 것이 교차 엔트로피입니다.
실습
1. 파이토치 – 단순 선형 회귀 예제
import torch
from torch import optim
# x, y 데이터 입력
# requires_grad: 각 텐서에 대한 연산추척, 역전파메서드 호출해 기울기를 계산하고 저장. PyTorch에서 자동으로 미분해주는 autograd 기능 사용여부
weight = torch.zeros(1, requires_grad=True)
bias = torch.zeros(1, requires_grad=True)
learning_rate = 0.001
#optim은 최적화 함수들이 모여있는 패키지
optimizer = optim.SGD([weight, bias], lr=learning_rate)
for epoch in range(10000):
hypothesis = weight * x + bias #가설
cost = torch.mean((hypothesis - y) ** 2) #오차계산 MSE
optimizer.zero_grad() #기울기값 0으로 초기화
cost.backward() #역전파 함수: 여기서 가중치와 편향에대한 기울기를 계산함.
optimizer.step() #여기서 학습률을 사용해 경사하강법 연산을 수행
if (epoch + 1) % 1000 == 0:
print(f"Epoch : {epoch+1:4d}, 가중치: {weight.item():.3f}, 편향: {bias.item():.3f}, 오차: {cost:.3f}")2. zero_grad(), cost.backward(), optimizer.step()
- zero_grad(): 기울기를 0으로 초기화해주는 함수
- cost.backward(): 역전파과정을 수행하며 기울기를 계산하는 함수
- optimizer.step(): 기울기를통해 경사하강법을수행하며 가중치를 조정하는 함수
for epoch in range(10000):
hypothesis = weight * x + bias
cost = torch.mean((hypothesis - y) ** 2)
print(f"Epoch : {epoch+1:4d}")
# [1]현재상태 출력
print(f"[1] : 기울기: {weight.grad}, 가중치: {weight.item():.3f}") # weight.grad, weight.item()
optimizer.zero_grad()
# [2]기울기 0으로 초기화
print(f"[2] : 기울기: {weight.grad}, 가중치: {weight.item():.3f}")
cost.backward()
# [3]기울기 계산
print(f"[3] : 기울기: {weight.grad}, 가중치: {weight.item():.3f}")
optimizer.step()
# [4]가중치 계산
print(f"[4] : 기울기: {weight.grad}, 가중치: {weight.item():.3f}")
if epoch == 3:
break3. 신경망 적용
PyTorch에서는 신경망 패키지를 제공한다. 기본적으로 bias는 사용함(True)로 되어있고 device나 dtype은 사용하지 않도록 되어있고
in_features와 out_features에는 입력 데이터 개수와 출력 데이터 개수를 지정해준다.
bias변수나 weight변수는 따로 필요없다 모델이 가지고 있기 때문에.
nnLinear = torch.nn.Linear(
in_features,
out_features,
bias=True,
device=None,
dtype=None
)import torch
from torch import nn # 신경망 import
from torch import optim
# 데이터 준비 (생략)
# device = "cuda" if torch.cuda.is_available() else "cpu" # Nvidia 그래픽카드
device = "mps" if torch.backends.mps.is_available() and torch.backends.mps.is_built() else "cpu" # MacOS GPU
model = nn.Linear(1, 1, device=device)
criterion = nn.MSELoss() # 위에서 우리가 계산했던 MSE오차를 계산해준다.
optimizer = optim.SGD(model.parameters(), lr=0.001) # 다른값들은 포함되어있으므로 lr만 추가로 지정해준다.
for epoch in range(10000):
output = model(x) # model에 입력값을 전달해주면 가설(함수)를 계산해 output변수에 넣어준다.
cost = criterion(output, y) # 위에서 지정해준 MSELoss()를 사용해 오차를 계산해준다.
optimizer.zero_grad()
cost.backward()
optimizer.step()
if (epoch + 1) % 1000 == 0:
print(f"Epoch : {epoch+1:4d}, Model : {list(model.parameters())}, Cost : {cost:.3f}")4. 가속기 자동선택 함수
def FindBestDevice():
"""
현재 시스템 환경에서 가장 성능이 좋은 디바이스를 반환합니다.
우선순위: CUDA(Nvidia) -> MPS(Apple) -> XPU(Intel) -> CPU
"""
# 1. Nvidia GPU (CUDA) 확인
if torch.cuda.is_available():
return torch.device("cuda")
# 2. Apple Silicon GPU (MPS) 확인
elif hasattr(torch.backends, "mps") and torch.backends.mps.is_available():
return torch.device("mps")
# 3. Intel GPU (XPU) 확인 - 리눅스/윈도우 서버 환경 대응
elif hasattr(torch, "xpu") and torch.xpu.is_available():
return torch.device("xpu")
# 4. 모든 조건이 안 맞으면 CPU 사용
else:
return torch.device("cpu")
# 위 함수를 사용하면
device = FindBestDevice() #구문을 이용해 device를 찾고
nn.Linear(1, 1, device=device) 이렇게 바로 넣어주면된다.
# 아래처럼 내장기능을 사용할수도있는데 현재 호환성 문제가 있음
if hasattr(torch, "accelerator"):
device = torch.accelerator.current_accelerator().type if torch.accelerator.is_available() else "cpu"5. DataSet & DataLoader
DataLoader는 Data를 불러오는 방식(batch_size, shuffle, num_workers)
DataSet은 불러온 데이터를 활용하기위해 정의된 클래스
DataSet과 DataLoader는 torch.utils.data 안에 포함되어있다.
DataLoader
- TensorDataset 인스턴스를 받음
- batch_size는 한번에 처리할 데이터 수
- shuffle은 학습데이터 순서를 섞을지 여부
- drop_last는 (배치 수)/(데이터 수) 했을때 나머지가있으면 이걸 버릴지 학습에 사용할지 여부
Batch Size
batch size는 모델 훈련에 큰 영향을 끼치는 요소기 때문에 신중하게 정해야한다. 보통은 8, 16은 작은사이즈, 32, 64는 보통(국룰) 128 256 512 1024는 큰 사이즈 로 본다. 당연히 데이터 크기도 고려되야한다. 데이터가 500갠데 batch size를 1024로 할수는 없는 법. 배치 사이즈를 키우면 LR도 같이 올려주기. (batch size가 2배가되면 데이터 양도 2배가되서 LR을 같이 늘려줘야 비슷하게 작동, 절대적인건 아님)
batch size를 키우면
- 학습 속도가 빨라짐
- GPU메모리를 초과하게되면 에러발생
- 과적합 발생 가능성 높음
batch size를 낮추면
- 학습 성능(모델의 예측 능력)면에서 유리함
- 일반화에 유리 (새로운 데이터에도 잘 적응하도록 만듬)
- 학습 속도는 느림
Bias (편향)
bias는 일반적으로 true를 씁니다 데이터 평균값을 0으로만들어주는 batch normalization(BN)을 쓸경우는 false를 쓰는것이 관례.
import torch
import pandas as pd
from torch import nn
from torch import optim
from torch.utils.data import Dataset, DataLoader, random_split, TensorDataset
# 데이터 준비 (생략)
# 데이터를 파이토치 DataSet으로 변환
train_dataset = TensorDataset(train_x, train_y)
# shuffle 훈련할때 사용하는 데이터 섞기
# drop_last 데이터크기가 5 배치크기가 2일때 나머지가 1개가 발생할경우 버릴지, 아니면 훈련데이터로 사용할지 여부.
# 특정상황에서 에러가날수있어서 사실상 거의 True 고정
train_dataloader = DataLoader(train_dataset, batch_size=2, shuffle=True, drop_last=True)
model = nn.Linear(2, 2, bias=True, device=device)
criterion = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.001)
for epoch in range(20000):
cost = 0.0
for batch in train_dataloader: # 배치마다 따로계산하기위해 반복문이 추가됨
x, y = batch
output = model(x)
loss = criterion(output, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
cost += loss # 1 epoch의 손실을 계산하기위해 데이터 누적
cost = cost / len(train_dataloader) # 데이터는 6개 배치사이즈는 2 -> 3으로 나눔
if (epoch + 1) % 1000 == 0:
print(len(train_dataloader))
print(f"Epoch : {epoch+1:4d}, Model : {list(model.parameters())}, Cost : {cost:.3f}")6. CustomDataset, CustomModel
우리는 위에서 Dataset이 뭔지 Model이 뭔지 이미 사용해봤다. Custom은 이들은 내 사용용도에 맞게 개조 및 자동화 시키기 위해 사용된다. 아래 코드의 주석부분을 읽어보면 자동화되는부분을 예시로 볼수있다.
CustomModel
class CustomModel(nn.Module): # nn.Module 상속
def __init__(self):
super().__init__() #부모 클래스의 생성자 호출
self.layer = nn.Linear(2, 1)
def forward(self, x):
x = self.layer(x)
return xCustomDataset
class CustomDataset(Dataset): # Dataset 상속
def __init__(self, file_path): # 파일경로를 인자로받아서
df = pd.read_csv(file_path) # read_csv()로 불러온다
self.x = df.iloc[:, 0].values # 0번 column의 데이터를 self.x에 저장
self.y = df.iloc[:, 1].values # 1번 column의 데이터를 self.y의 저장
self.length = len(df)
def __getitem__(self, index):
x = torch.FloatTensor([self.x[index] ** 2, self.x[index]])
y = torch.FloatTensor([self.y[index]])
return x, y
def __len__(self):
return self.length