
seq2seq
이 수식을 기억하시나요?
p(y1,…,yT′∣x1,…,xT)=Πt=1T′p(yt∣v,y1,…,yt−1)
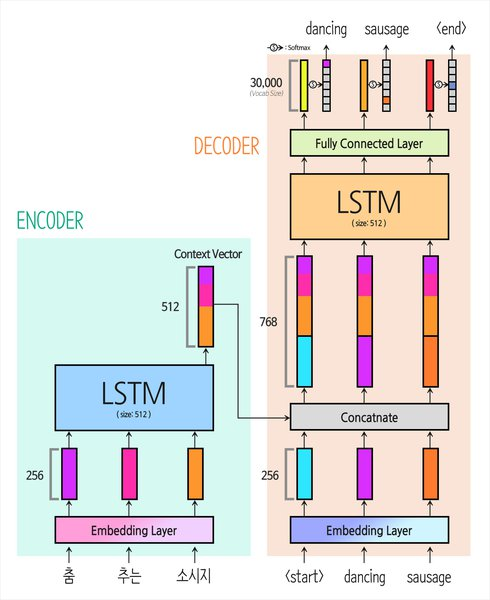
Encoder가 생성한 컨텍스트 벡터 v 를 Embedding 레이어를 거친 y 값에 Concatnate하여 위 수식을 비로소 만족하게 됩니다. 우리가 Seq2seq를 완성한 거죠!
LSTM Encoder
import torch.nn as nn
class Encoder(nn.Module):
def __init__(self, input_dim, emb_dim, hidden_dim):
super().__init__()
self.embedding = nn.Embedding(input_dim, emb_dim)
self.rnn = nn.LSTM(emb_dim, hidden_dim, batch_first=True)
def forward(self, src):
print("입력 Shape:", src.size())
embedded = self.embedding(src)
print("Embedding Layer를 거친 Shape:", embedded.size())
outputs, (h_0, c_0) = self.rnn(embedded)
print("LSTM Layer의 Output Shape:", outputs.size())
print("LSTM Layer의 Hidden State Shape:", h_0.size())
print("LSTM Layer의 Cell State Shape:", c_0.size())
return outputs, h_0, c_0Embedding 레이어를 단어 사이즈와 Embedding 차원에 대해 선언을 한 후, 논문에서 소개한 대로 torch.nn.LSTM(enc_units)으로 LSTM을 정의합니다. Pytorch 속 LSTM 모듈의 기본 반환 값은 최종 State 값이므로 return_sequences 나 return_state 값은 따로 조정하지 않습니다 (기본: False). 즉, 우리가 정의해 준 Encoder 클래스의 반환 값이 곧 컨텍스트 벡터(Context Vector) 가 되는 겁니다. 추가적인 옵션이 궁금하시다면 아래의 Pytorch LSTM 공식 문서를 참조하시면 좋습니다.
vocab_size = 30000
emb_size = 256
lstm_size = 512
batch_size = 1
sample_seq_len = 3
print("Vocab Size: {0}".format(vocab_size))
print("Embedidng Size: {0}".format(emb_size))
print("LSTM Size: {0}".format(lstm_size))
print("Batch Size: {0}".format(batch_size))
print("Sample Sequence Length: {0}\n".format(sample_seq_len))Vocab Size: 30000
Embedidng Size: 256
LSTM Size: 512
Batch Size: 1
Sample Sequence Length: 3import torch
encoder = Encoder(vocab_size, emb_size, lstm_size)
sample_input = torch.randint(0, vocab_size, (batch_size, sample_seq_len))
sample_output, hidden, cell = encoder(sample_input)LSTM Decoder
class Decoder(nn.Module):
def init(self, vocab_size, embedding_dim, hidden_dim):
super(Decoder, self).init()
self.embedding = nn.Embedding(vocab_size, embedding_dim)
self.lstm = nn.LSTM(embedding_dim + hidden_dim, hidden_dim, batch_first=True)
self.fc = nn.Linear(hidden_dim, vocab_size)
def forward(self, x, hidden, cell, context):
print("입력 Shape:", x.size())
embedded = self.embedding(x)
print("Embedding Layer를 거친 Shape:", embedded.size())
embedded = torch.cat((embedded, context), dim=2)
print("Context Vector가 더해진 Shape:", embedded.size())
output, (hidden, cell) = self.lstm(embedded, (hidden, cell))
print("LSTM Layer의 Output Shape:", output.size())
output = self.fc(output)
print("Decoder 최종 Output Shape:", output.size())
return output, hidden, cellDecoder는 Encoder와 구조적으로 유사하지만 결과물을 생성해야 하므로 Fully Connected 레이어가 추가되었고, 출력값을 확률로 변환해 주는 Softmax 함수도 추가되었습니다 (Softmax는 모델 내부에 포함시키지 않아도 훈련 과정에서 포함시키는 방법도 있습니다). 그리고 Decoder가 매 스텝 생성하는 출력은 우리가 원하는 번역 결과에 해당하므로 LSTM 레이어의 return_sequences 변수를 True로 설정하여 State 값이 아닌 Sequence 값을 출력으로 받습니다.
print("Vocab Size: {0}".format(vocab_size))
print("Embedidng Size: {0}".format(emb_size))
print("LSTM Size: {0}".format(lstm_size))
print("Batch Size: {0}".format(batch_size))
print("Sample Sequence Length: {0}\n".format(sample_seq_len))decoder_input = torch.randint(0, vocab_size, (batch_size, sample_seq_len)) # (batch_size, seq_length)
decoder = Decoder(vocab_size, emb_size, lstm_size)
dec_output, hidden, cell = decoder(decoder_input, hidden, cell, sample_output)