
과대적합과 과소적합
딥러닝 기초에서는 각종 용어들과 파이토치 기본 사용법을 알아보았습니다 심화 학습에서는 과대적합 과소적합때문에 발생하는 성능저하를 어떻게 개선할것인지 알아보도록 하겠습니다. 또 새로운용어들도 존재하지만 대부분 기초학습때 배웠던것이니 걱정하지 않으셔도 됩니다.
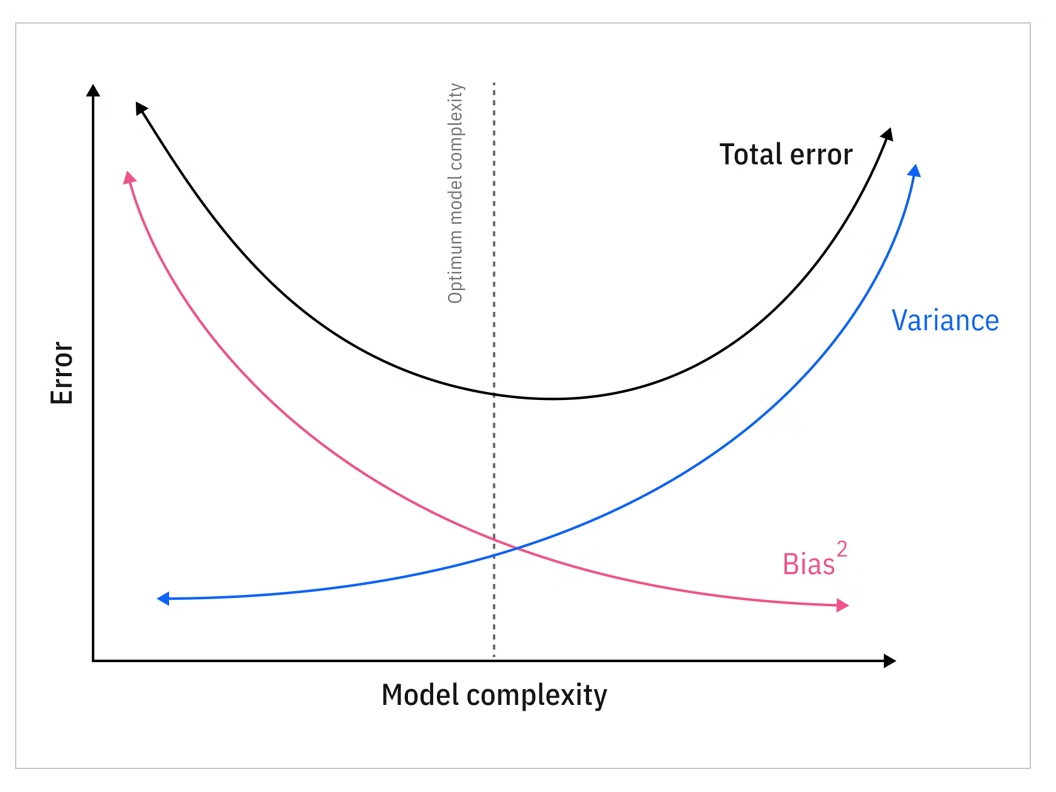
편향-분산 트레이드 오프
실제로는 아래 그래프와 완전히 동일하진 않겠지만 편향과 분산은 서로 트레이드 오프관계이므로 적절한 조절을통해 Total error를 줄이는것이 중요합니다.
- Variance = 분산: 훈련 데이터셋이 조금만 바뀌어도 모델의 예측값이 크게 요동치는 정도. 차이가 클수록 더욱 과적합 된것. 가중치 값이 크다는것은 입력값에 대해 모델이 매우 민감하게 반응 한다는 뜻이기도함. L2 정규화 (Weight Decay)로 가중치 크기를 줄이면 Variance도 같이 낮아지는 효과가 있음.
- Feature의 종류 수가 많아지만 Variance 도 높아짐.
- Bias = 편향
과대적합과 과소적합 문제 해결
- 데이터 수집: 과소적합이 발생한경우 데이터 양이 부족한것이므로 데이터를 늘려줘야한다. 혹은 데이터 양이 부족하더라도 모델 변경을통해 개선이 되기도한다.
- 피처 엔지니어링: 추가 데이터 수집이 어려운 경우, 기존 훈련 데이터에서 변수나 특징을 추출하거나, 피처를 더 작은 차원으로 축소한다.
- 모델 변경: 잘못된 모델 선택으로 과대적합이나 과소적합이 발생할 수 있는데 데이터 세트에비해 너무 강력한 모델을 쓴다거나 너무 간단한 모델을 사용 하는경우.
- 조기 중단: 모델 학습 시 검증 데이터세트로 성능을 지속적으로 평가해 모델의 성능이 저하되기 전에 모델 학습을 조기 중단 하는 방법(Early Stopping)
- 배치 정규화: 모델의 계층마다 편향과 분산을 조정해 내부 공변량 변화를 줄여 과대적합을 방지한다.
- 가중치 초기화: 모델의 매개변수를 최적화 하기 전에 가중치 초기값을 설정하는 프로세스를 의미한다. 학습 시 기울기가 매우 작아지거나 커지는 문제가 발생할 수 있다. 이러한 문제는 학습을 어렵게 만들거나 불가능 하게 만든다. 그러므로 적절한 초기 가중치를 설정해 과대 적합을 방지할 수 있다.
- 정칙화: 모델에 정칙화를 적용해 목적 함수에 패널티를 부여하는 방법이다. 모델을 일부 제한해 과대적합을 방지할 수 있다. 정칙화에는 학습 조기 중단, L1 정칙화, L2정칙화, 드롭아웃, 가중치 감쇠 등이 있다.
Standardization 표준화 – 표준편차를 1로 만드는 과정
Instance Normalization
만약 배열에 데이터가 [1, 0.01, 0.01]이 있으면 배열의 표준화 결과는 [1.4142, -0.707, -0.707]이 된다.
1. 평균계산
2. 분산 및 표준편차 계산
각 데이터에서 편균값을 뺀 값의 제곱합을 구하여 분산
3. 표준화화 마무리
정규화를 하는 이유는 내부 공변량 변화를 억제 + 기울기 소실 방지 하기 위해서다.
정규화의 종류
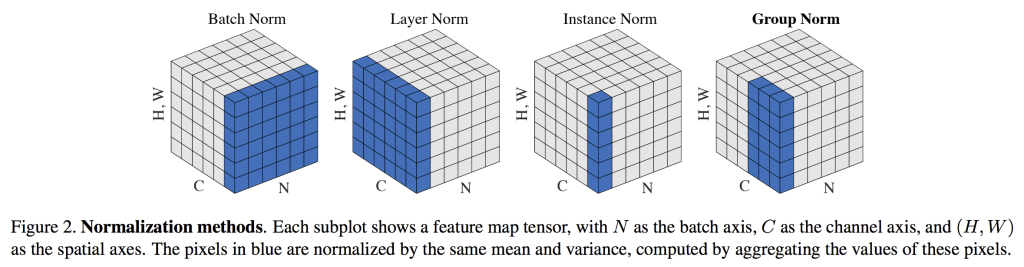
- N (Batch Size): 배치 크기, 한번에 학습 시킬 데이터 수
- C (Channels): 채널 수, 컬러 사진은 보통 RGB 3개의 채널을 가짐
- H (Height): 이미지의 세로 픽셀수
- W (Width): 이미지의 가로 픽셀수
- Batch Norm(배치 정규화) – 배치정규화는 이미지 분류 모델에서 적용시 14배 더 적은 학습으로도 동일한 정확도를 달성. 이미지 분류에서 학습 빠름. CNN(합성곱) MLP 같은 순방향 신경망 (Feedforward Neural Network, FNN)에서 주로 사용.
- Layer Norm(계층 정규화) – 이미지 데이터 전체를 정규화 하지않고 채널별로 정규화 수행. 미니 배치 샘플과 의존관계가 없음. 샘플이 전혀 다른 길이를 가지더라도 정규화 가능. 자연어처리 (NLP), 순환신경망(RNN)이나 트랜스포머(Transformer)기반 모델에서 주로 사용.
- Instance Norm(인스턴스 정규화) – 채널과 샘플 기준으로 정규화. 정규화가 각 샘플에 대해 개별적으로 수행되므로 입력이 다른 분포를 갖는 작업에 적합하다. 그래서, 인스턴스 정규화는 생성적 적대 신경망 (GAN)이나 이미지의 스타일을 변환하는 스타일 변환(Style Transfer) 모델에서 주로 사용된다.
- Group Norm(그룹 정규화) – 채널을 N개의 그룹으로 나누고, 각 그룹내에서 정규화 수행. 그룹을 하나로 설정하면 인스턴스 정규화와 동일. 배치의 크기가 작거나 채널 수가 매우 많은 경우에 주로 사용된다. 합성곱 신경망(CNN)의 배치 크기가 작으면 배치 정규화가 데이터셋을 대표한다고 보기 어렵기때문에 배치정규화 대안으로 사용된다.
가중치 감쇠
다양한 방법으로 가중치를 초기화 할수있음
정칙화 (Regularization)
과대적합되지 않도록 손실 함수에 패널티를 가하는 방식이다.
- L1 정칙화 (Lasso): L1 Norm은 벡터 또는 행렬값의 절댓값 합계를 계산한다. 이러한 방식을 차용해 L1 정칙화는 손실 함수에 가중치 절댓값의 합을 추가해 과대적합을 방지한다. 일부 가중치를 정확히 0으로 만들어 희소(Sparse) 모델을 만듭니다.
단점: 무거움, 미분 사용 불가 - L2 정칙화 (Ridge): L2 Norm은 벡터 또는 행렬의 크기를 계산한다. 이러한 방식을 차용해 L2 정칙화는 손실함수에 가중치 제곱의 합을 추가해서 과대적합 방지한다.
가중치를 0에 가깝지 만들지만 완전히 0으로 만들지는 않아 모든 특성을 고르게 합니다. - 가중치 감쇠: 가중치 감쇠는 loss function이 아닌optimizer에 weight_decay 계수를 이용해서 적용한다. L2 정규화와 동일한 방식인데 파이토치 에서는 가중치 감쇠 방식을 권장함.
- 모멘텀: 이전 기울기를 고려해 가중치를 갱신 (관성 때문에 보폭이 커짐). 변경된 가중치로 local minima 뛰어넘기 가 목표
- 엘라스틱 넷: L1 L2 정칙화를 결합해서 희소성 안정성 둘다 얻을수 있음.
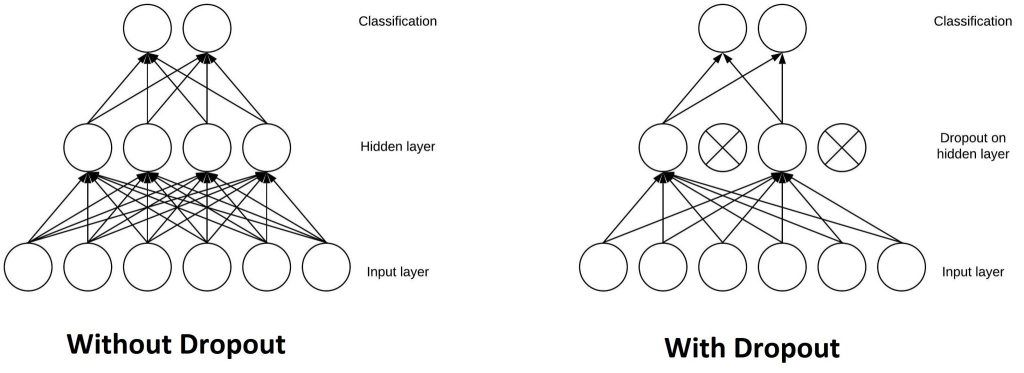
- 드롭아웃: 훈련중 일부 노드를 일정 비율로 제거하거나 0으로 설정해 과대적합을 막음.
- 그래디언트 클리핑: 기울기가 너무 커지는 현상을 방지
데이터 증강 및 변환
머신러닝은 비슷해도 다른데이터라면 데이터가 더많은쪽이 모델 훈련에 도움이 된다. 머신러닝은 사람과 달라서 “1 + 3” 이랑 “3 + 1” 을 다르게 인식한다. 다른 예를 들자면 손 사진을 학습시켜서 이미지가 손인지 아닌지 구분하는 모델을 만들어도 이미지가 90도 회전하면 구분하지 못한다. 그래서 데이터를 지지고 볶으면서 변형시켜서 뻥튀기해주면 모델훈련에 도움이 된다는 이야기.
데이터 증강은 과대적합을 줄이고 일반화 능력을 향상시킴
텍스트 데이터
문서 분류 및 요약 문장 번역 과 같은 자연어 처리 모델을 구성할 때, 데이터 셋의 크기를 늘리기위해 사용. 예를들면, 자연어 처리 데이터 증간(NLPAUG) 라이브러리가 있음.
Aug 목록
삽입은 단어 또는 문장의 의미에 영향을 끼치지않는 수식어 등을 추가하는 방법. 삭제는 반대로 의미에 영향을 끼치지않는 수식어를 삭제 하는 방법.
너무 적은량을 삽입하거나 삭제하면 (기존 데이터와 큰 차이가 없으면) 과대적합이 발생함
- ContextualWordEmbsAug (삽입): BERT 모델을 활용해 단어를 삽입하는 기능 부사 형용사등을 추가.
- RandomCharAug (삭제): 단어중 알파벳 일부분을 랜덤하게 삭제 (약 75%단어는 그대로) 문장이 망가짐.
- RandomWordAug (대체): 문장내 단어들의 랜덤하게 교체되서 순서가 바뀜 문장이 망가짐.
- SynonymAug (대체): 단어를 유의어로 대체하거나 관계대명사처럼 who that 같이 줄여진걸 랜덤하게 명시화시켜줌. 문장이 구체적으로 변함. 하지만 문맥을 파악하지않고 단순히 DB에서 유의어로 정의된 단어들로 교체되는거라 문맥이 변할수있음.
- ReservedAug (대체): can cannot 등의 단어가 reserved_tokens에 존재하는 값으로 변경됨. (cannot -> can’t) 케이스도 있어서 항상 의미가 반대가 되는건 아님.
- BackTranslationAug (역번역): 예를들어 원문이 영어일때 영어->한국어->영어로 번역해서 비슷한의미의 다른 문장으로 바꿔버림.
이미지 데이터
텍스트 데이터와 마찬가지로 데이터셋의 크기를 키우기위해 사용된다.
torchvision 라이브러리와 이미지 증강(imgaug) 라이브러리 둘다 클래스들을 가지고있다.
타입 변환 방법
라이브러리가 여러종류이다보니 각각의 클래스가 있다.
torchvision에는 transforms 라는 모듈이 변환 기능을 가지고있다.
회전 및 대칭
데이터 수집시 모든 방향의 회전되거나 대칭되는 이미지를 수집하기 어렵기때문에 회전및 대칭으로 데이터 증강을 하면 데이터의 크기를 늘릴수있다. 모든 경우의수를 만들지는 않는것 같다
자르기 및 패딩
… 너무 예시가 많고 다양한데 데이터를 다양하게해서 크기를 키우는거말고는 특징을 알기힘들어 스킵하겠음. 책을 보세요. 검색하거나 이미지증강모델 이런식으로 검색 하세요.
전이학습
사전에 학습된 모델(업스트림) 시스템에 맞는 새로운 모델로 추가 학습하는 과정. 이렇게 전이학습이 완료된 모델을 (다운스트림) 이라고 한다.
미세조정 (Fine-tuning)
사전학습된 모델을 불러와서 일부 특징을 freeze(동결)시키고 나머지부분을 새로운 문제에맞게 수정합니다. 이 후 fit을 돌리면 모델이 새로만든 뒷부분만 수정하게됩니다.
어느정도 학습이 되면 앞부분을 다시 Unfreeze 시키고 모델 전체 혹은 일부를 다시 fit을 시키면 이게 미세조정 입니다.
결론적으로 이미 학습된 모델을 살짝 조정해주는겁니다.
귀납적 전이 학습
기존에 존재하는 모델을 새로운 모델로 수정해주는것으로 두 종류가 있다.
자기주도적 학습(Self-taught Learning) – 비지도 전이학습
소스 도메인의 데이터셋의 크기는 크지만 레이블링 된 데이터수가 매우 적거나 없을때 사용.
다중 작업 학습(Multi-task Learning)
모델에게 여러 작업을 동시에 가르치는 방법을 말한다. 예를들어 자동주행 모델같은경우는 영상이미지를 가지고 차선도 찾고, 표지만도 읽고, 사물도 동시에 인식해야하는 경우를 말함.
다중 작업 모델의경우 계층이 두가지로 나뉘는데
- 공유계층: 모델 입력층 부분에서 공통적으로 사용하는 부분. 공용 특징이있다면 (General Features) 라고 부름.
- 작업별 계층: 반대로 각 작업에 특화된 특징들도 존재하고 각 작업마다
변환 전이 학습 (Inductive Transfer Learning)
가장 일반적인 형태의 전이 학습입니다. 출발지(Source)와 목적지(Target)의 작업(Task)이 서로 다를 때 사용합니다.
- 언제 쓰나?: 내가 해결하려는 문제의 데이터(라벨링 된 것)가 부족하지만, 비슷한 구조의 대규모 데이터로 학습된 사전 모델이 있을 때 씁니다.
- 특징: 이미 학습된 모델(예: 사물 인식 모델)을 가져와서 새로운 작업(예: 암 세포 진단)에 맞게 미세조정(Fine-tuning)합니다.
- 차이점: 목적지 데이터에 **라벨(Label)**이 반드시 있어야 합니다.
비지도 전이 학습 (Unsupervised Transfer Learning)
출발지와 목적지 모두 라벨이 없는(Unlabeled) 상태에서 지식을 전달하는 방식입니다.
- 특징: 데이터의 정답을 맞히는 게 아니라, 데이터 자체의 **표현(Representation)**이나 구조를 학습하는 데 집중합니다.
- 차이점: 라벨링 비용이 전혀 들지 않지만, 학습이 까다롭습니다. 최근에는 자기지도학습(Self-supervised learning)과 결합되어 많이 쓰입니다.
- 언제 쓰나?: 데이터는 산더미처럼 많지만, 일일이 정답(라벨)을 달기 어려운 상황에서 데이터의 핵심 특징만 먼저 뽑아내고 싶을 때 씁니다.
제로-샷 전이 학습 (Zero-shot Learning)
모델이 학습 과정에서 단 한 번도 본 적 없는 클래스를 추론하는 놀라운 방식입니다.
- 특징: 사물의 ‘이름’ 대신 ‘속성(Attribute)’을 학습합니다. 예를 들어 “줄무늬가 있고, 말처럼 생겼어”라는 설명을 들으면, 얼룩말을 본 적 없어도 “아, 저게 얼룩말이구나”라고 맞히는 식입니다.
- 차이점: 학습 데이터와 테스트 데이터의 클래스가 완전히 겹치지 않습니다.
- 언제 쓰나?: 새로운 카테고리가 계속 추가되어서 매번 다시 학습시키기 불가능한 경우(예: 신종 상품 분류)나 데이터 구하기가 하늘의 별 따기인 경우에 씁니다.
원-샷 전이 학습 (One-shot Learning)
새로운 클래스에 대해 **단 한 개의 데이터(이미지/텍스트)**만 보고도 학습을 완료하는 방식입니다.
- 특징: 주로 ‘비교’를 배웁니다. 두 데이터가 “같은가, 다른가”를 판단하는 능력을 길러서, 처음 보는 데이터라도 기준점과 비교해 정체를 파악합니다.
- 차이점: 제로-샷보다는 낫지만, 여전히 극도로 적은 데이터로 성능을 내야 합니다.
- 언제 쓰나?: 지문 인식, 얼굴 인식처럼 한 사람당 데이터가 한두 개뿐인 보안 시스템에서 주로 사용됩니다.
| 구분 | 목적지 데이터(Target) | 핵심 전략 | 대표 사례 |
| 변환 | 라벨 있음 (적음) | 미세조정 (Fine-tuning) | 개 분류 모델 → 고양이 분류 |
| 비지도 | 라벨 없음 | 특징 추출 (Feature Extraction) | 뉴스 텍스트 자동 군집화 |
| 제로-샷 | 라벨 없음 (설명만 있음) | 속성/텍스트 연관 학습 | “날개 달린 말” 설명으로 페가수스 찾기 |
| 원-샷 | 라벨 1개 있음 | 유사도 비교 (Similarity) | 스마트폰 얼굴 인식 잠금 해제 |