
CV에서 사용되는 모델들
CV는 컴퓨터 비전의 약자로 컴퓨터(인공지능)에 눈에 해당하는 기술이라고 보면됩니다. CG는 컴퓨터 그래픽으로 사람들이 정보를 다넣어준걸 컴퓨터를통해 가공하고 보여주는 기술이었다면. CV는 딥러닝을통해 인공지능이 사물을 구분하게하거나 심지어 요즘에는 생성형 AI기술을통해 이렇게 학습한것을 토대로 새로운 이미지를 만들어내기까지합니다. 2023년부터 2026년 현재까지 매우 급속도로 발전하고있습니다.
아래 영상은 윌스미스가 스파게티 먹는 영상을 생성형AI로 만든것인데 2년만에 엄청난 발전을 한것을 한눈에 봐도 알 수 있습니다. 참고로 2025년 예시는 출력이 엄청 잘 된 케이스이고 평균적으로는 저런 영상 만드는게 쉽지 않았었습니다. 2024년 12월에 는 Sora AI가 나와서 높은 퀄리티에 세상을 놀래켰는데 이후 2025년 2월 X의 Grok 5월에 구글의 Veo등이 나오면서 Sora AI는 서비스종료 절차에 들어갔을정도로 지금 현재 발전속도는 매우 빠르게 바뀌고있습니다.
이 글에서는 생성형 AI 모델을 다루지는 않습니다.
ArexNet, VGG, ResNet
ArexNet, VGG, ResNet은 각각 2012, 2014, 2015년에 높은성적을 거두며 유명해진 모델입니다. 이 모델들의 특징은
- ArexNet: Deep Learning의 서막 GPU사용으로 속도가 급속도로 빨라졌고 ReLU 활성화 함수와 Dropout을 대중화 시킴.
- VGG: Convolutional layer에서 3×3 작은 필터만 깊게 쌓아도 성능이 좋아진다는것을 증명하고, 구조가 간단하여 오랫동안 기본 모델(Backbone)으로 사랑받았습니다.
- ResNet: 층을 너무 깊게 쌓으면 기울기소실문제로 학습이 안되는 문제를 Skip Connection으로 해결해서 성능을 더욱 높였습니다 최고 높은 층은 152층인데 깊은 층이 항상 좋은결과를 내놓는것은 아니라서 여러 층으로된 다양한 모델이 있습니다.
현재 ArexNet과 VGG는 사실상 Baseline 학습용 으로 사용되고, ResNet은 여전히 현역이자 산업계의 표준이라고 봐도 될정도입니다. 다만 VGG는 모델 자체를 추론용으로 사용하지는 않지만 VGG의 학습과정에서 사용되는 특성추출기나 이미지 스타일 변환 알고리즘은 2026년 현재까지도 사용되고 있습니다. 학습된 모델 용량이 크다는 단점도 있습니다.
최근에는 Vision Transformer (ViT)와 EfficientNet 계열이 그 자리를 대체하고 있는 추세입니다. 하지만 ResNet이 여전히 ViT보다 속도는 빠르면서 정확도는 큰차이가 없는 경우가 많습니다. 이런 이유로, 의료Ai, 자율주행, 보안시스템 등 안정성이 중요한 도메인에서는 ResNet50이나 ResNet101이 가장 먼저 고려된다고 합니다.
2026년 현재 잘 나가는 모델
Vision Transformer (ViT) & Swin Transformer: * 이미지를 조각(Patch)으로 나눠 ‘어텐션(Attention)’ 메커니즘을 적용합니다.
- 특징: 데이터가 아주 많을 때 CNN 계열보다 훨씬 정교한 성능을 냅니다. 현재 컴퓨터 비전 연구의 주류입니다.
EfficientNetV2 & ConvNeXt: * 특징: ResNet의 안정성과 ViT의 효율성을 합친 모델들입니다. 연산량 대비 성능이 압도적이라 가성비를 따지는 상용 서비스에서 가장 많이 채택됩니다.
MobileNetV3 / FastViT: * 특징: 스마트폰이나 임베디드 기기에서 실시간으로 돌아가야 할 때 씁니다.
CV 관련 용어 + 개념정리
Tensor: n차원의 데이터를 담는 데이터타입 (그냥 머신러닝의 텐서와 같음)
Convolution 연산 (합성곱 연산): 필터를 통해 데이터에서 의미 있는 특징(Feature)을 추출하는 과정
- 선(Edge) 추출: 수직 필터를 쓰면 세로선이 강조된 결과물이 나옵니다.
- 블러(Blur) / 샤프닝(Sharpen): 주변 픽셀을 뭉개거나 차이를 벌려 이미지의 질감을 바꿉니다.
- 핵심: 필터에 어떤 숫자가 적혀 있느냐에 따라 “고양이 귀 모양”, “강아지 코 모양” 등을 찾아내는 감지기가 됩니다.
Convolution 연산중 가중치
Filter (CNN): 이미지에서 특정 패턴을 찾아내는 돋보기 or 특성 추출기
Stride (CNN): 필터로 이미지 구석 구석을 검사할 때, 한번에 이동하는 보폭 (픽셀단위)
Stride의 동작 방식
- Stride = 1 (기본값): 필터를 오른쪽으로 1픽셀씩 이동시킵니다. 이미지를 아주 꼼꼼하게 훑기 때문에 정보 손실이 적지만, 연산량이 많고 출력 결과물(Feature Map)의 크기가 크게 줄어들지 않습니다.
- Stride = 2 이상: 필터를 2픽셀(또는 그 이상)씩 건너뛰며 이동시킵니다. 이미지를 듬성듬성 보기 때문에 출력물의 크기가 절반 이하로 확 줄어듭니다.
왜 Stride를 조절하나요? (역할)
- 이미지 크기 축소 (Downsampling): Pooling(풀링) 층과 비슷하게 이미지의 해상도를 줄이는 역할을 합니다. 층이 깊어질수록 Stride를 키워 이미지 크기를 줄이고, 대신 더 중요한 “추상적인 특징”에 집중하게 만듭니다.
- 연산 효율성: 보폭을 크게 하면 계산해야 할 지점이 줄어들기 때문에 학습 및 추론 속도가 빨라집니다.
- 넓은 시야 (Receptive Field): 보폭을 크게 가져가면 같은 횟수의 연산으로도 이미지의 더 넓은 영역을 한눈에 파악할 수 있게 됩니다.
Receptive field:
Padding: 패딩이란 필터로 이미지를 스캔할때 학습 이미지를 감싸는 것을 말합니다.
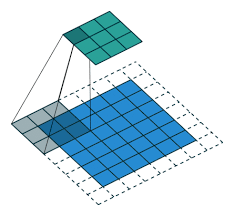
- Border 정보 손실 방지: 그림을 보면 3×3필터가있을때 패딩이 없다면, 가장 구석의 픽셀은 1번밖에 참조 되지 않습니다. 중앙쪽 다른 픽셀들은 3×3필터 사용시 9번씩 참조되는데 비교하자면 코너의 픽셀은 거의 무시된다고 생각해도 될 정도입니다.
- 이미지 크기 감소 방지: 단순히 코너의 픽셀이 무시되는것 뿐만 아니라, 패딩이 없다면 필터를 사용할때마다 이미지 크기가 급격히 줄어듭니다. 크기가 너무 빨리 줄어들면 Deep Network를 유지하기 힘듭니다.
Feature map: 합성곱 연산의 최종 결과물 aka Activation Map
Channel: 각 필터 레이어 연산의 결과물
Inductive bias(귀납적 편향): 머신러닝 모델이 학습 데이터에서 보지 못한 새로운 데이터(Unseen Data)에 대해 예측할 때, “아마 이럴 것이다”라고 미리 가정하고 들어가는 일종의 ‘사전 지식’ 또는 ‘선입견’을 의미합니다. 학습 데이터는 유한하지만 우리가 예측해야 할 미래의 상황은 무한하기 때문에, 모델이 올바른 방향으로 학습하려면 적절한 고정관념(Bias)이 반드시 필요합니다.
모델별 Inductive Bias의 차이
| 모델 종류 | Inductive Bias의 강도 | 주요 가정 (Assumptions) |
| Fully Connected (MLP) | 매우 약함 | 데이터 간의 특별한 관계가 없다고 가정 (모든 입력이 연결됨) |
| CNN | 강함 | 데이터가 공간적인 특징(이미지 등)을 가진다고 가정 |
| RNN | 강함 | 데이터가 시간적인 순서(문장, 주식 등)를 가진다고 가정 |
| Transformer (ViT) | 약함 | 특별한 가정 없이 데이터 전체의 관계(Attention)를 스스로 학습 |
Layer마다 여러개의 Filter가 필요한 이유?
“필터 개수 = 모델이 한 번에 고려할 수 있는 특징의 종류 수”
다양한 관점의 특징 추출 (Feature Diversity)
필터 하나는 오직 한 가지 종류의 패턴만 찾을 수 있습니다.
- 필터 A: 가로선($-$)만 찾음
- 필터 B: 세로선($|$)만 찾음
- 필터 C: 대각선($/$)만 찾음
만약 레이어에 필터가 하나뿐이라면, 그 레이어는 이미지에서 오직 ‘가로선’ 정보만 남기고 나머지는 다 버리게 됩니다. 강아지의 눈, 코, 입을 모두 인식하려면 각각의 모양을 담당할 수 있는 수십, 수백 개의 다양한 필터가 동시에 필요합니다.
고차원적 정보의 조합 (Hierarchical Representation)
층(Layer)이 깊어질수록 필터들이 하는 일은 점점 더 복잡해집니다.
- 초반 레이어 (예: 64개 필터): 아주 기본적인 선이나 색상의 방향을 찾습니다.
- 중반 레이어 (예: 128~256개 필터): 앞 단계에서 찾은 선들을 조합해 ‘곡선’, ‘삼각형’, ‘질감’ 등을 찾습니다.
- 후반 레이어 (예: 512개 필터): 더 복잡해진 정보들을 조합해 ‘귀 모양’, ‘꼬리 모양’, ‘눈동자’ 같은 구체적인 부품들을 인식합니다.
Filter 각각의 수치는 무엇을 의미하나요? 필터 안의 수치는 “특정 패턴에 대한 가중치(Weight)”를 의미합니다. 다르게 말하면 특정 특징에대한 점수 라고 생각하면됩니다. 예를들어 고양이 귀를 판별하는 필터가 있다고 하면 그 필터를 거쳐서 나온 채널의 픽셀값(즉 필터값)은 해당 위치마다 고양이귀 형태가 있는 또는 있는것으로 보이는 확률이 남아있다고 보면 될거같네요.
CNN 연산 결과 출력은 무엇을 의미하나요? 여러개의 출력은 왜 생기고, 어떻게 활용되나요?
CNN 연산의 최종 출력은 한마디로 “입력 이미지에 대한 다각도의 분석 보고서”라고 할 수 있습니다. 따라서 CNN의 중간 연산 결과물인 Feature Map은 이미지의 특정 위치에 우리가 찾는 Feature가 얼마나 강하게 나타나는지를 숫자로 나타낸것
- 높은 숫자: 내가 찾는 패턴(고양이 귀) 가 여기 거의 확실히 있다!!
- 0에 가까운 숫자: 해당 패턴이 전혀 보이지 않는다.
이미지에서 패턴은 이미지 안에 존재하고, CNN에서는 Filter를 사용해서 패턴을 감지하고, 이를 잘 감지하는 방향으로 수정된다.
CNN에서 각 Layer별 수행되는 기법들은 어떤 의미가 있나요?
- Convolution Layer: 특징 추출
- Activation(ReLU 등): 합성곱 연산 결과에 활성화 함수 적용하는 단계
- Pooling: 요약 과 불변성: Feature Map의 크기를 줄여 핵심만 남기는 과정
- Flatten: 여러 filter를 거치면 3차원덩어리가 길게 펼쳐지는 과정. Flatten 이후 Dense Layer에 넣어서 1D Vector가 되면 이때부터는 Feature Map이 아니라 Feature Vector 라고함.
- FC Layer: 최종 판단 (Classification) 모델의 맨 마지막에 위치하며, 추출된 모든 정보를 종합합니다.
최종 판단하는 방법
종합 보고서: 앞선 층들이 “눈이 있고, 귀가 있고, 털이 있다”는 단서들을 찾아냈다면, FC Layer는 이 단서들의 점수를 다 합쳐서 **”결국 이 사진은 95% 확률로 강아지다”**라는 결론을 내립니다.
ResNet
용어 정리
잔차 연결 (residual connection) (aka 스킵 연결, 단축 연결): 층을 통과할때 공부한 내용만 넘기지 말고, 공부하기 전 원본 데이터도 같이 넘기는 방식. 아무리작아져도 1에 수렴하지 0에 가까워지지 않아서, 기울기 소실 문제를 막을수 있음.
# Output = F(x) + x
def forward(self, x):
identity = x # 1. 일단 원본(x)을 따로 보관해둔다 (Identity)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out) # 2. 두 번의 컨볼루션을 거친 결과물 (F(x))
out += identity # 3. 핵심! 보관해둔 원본을 결과에 그냥 '더해준다' (Skip Connection)
out = self.relu(out)
return out병목 블록 (Bottleneck Block):
“비싼 연산을 싸게 하기 위해, 데이터를 좁은 길(병목)로 통과시켜서 연산량을 다이어트하는 구조”입니다.
- 목적: 연산량 다이어트
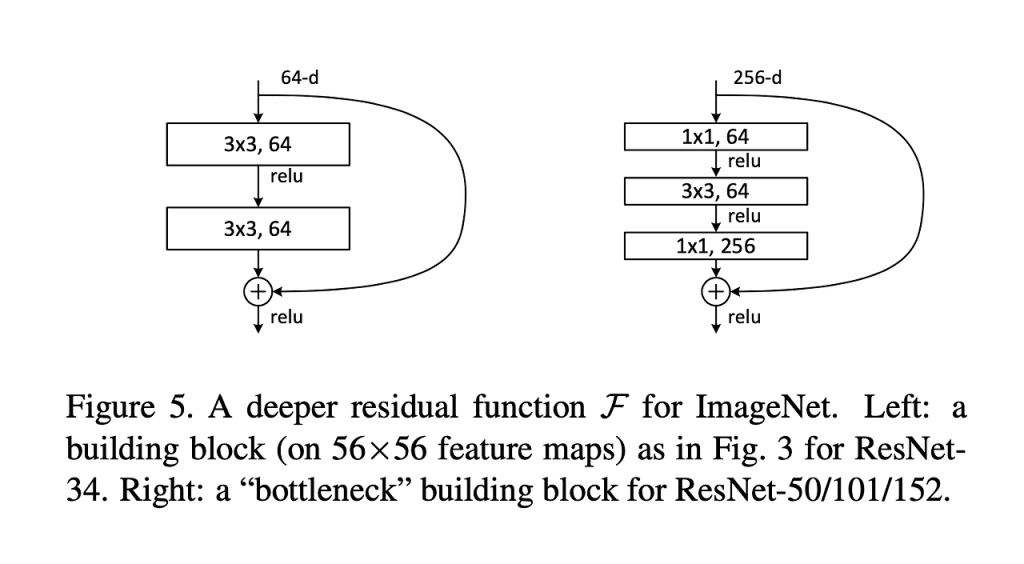
일반 블록 vs 병렬 블록 비교
1. 전제 조건 (Input & Output)
- 입력 데이터: 256개 채널 (가로 28 x 세로 28 크기의 특징 맵)
- 출력 데이터: 동일하게 256개 채널로 내보내야 함
- 커널 크기: 가장 비싼 3×3 연산을 기준으로 함
2. [기본 블록] 연산량 계산
기본 블록은 3 x 3 컨볼루션을 두 번 수행합니다. (256 -> 256 -> 256)
- 첫 번째 3 x 3 Conv: 3 x 3 x 256(입력) x 256(출력) x 28 x 28 = 약 4.62 억 번
- 두 번째 3 x 3 Conv: 위와 동일하게 4.62 억 번
- 총합: 약 9.24억 번 연산
3. [병목 블록] 연산량 계산 (다이어트 시작)
병목 블록은 채널을 $1/4$로 줄였다가($64$) 다시 늘립니다. ($256 \rightarrow 64 \rightarrow 64 \rightarrow 256$)
- 첫 번째 1 x 1 Conv (축소): 1 x 1 x 256 x 64 x 28 x 28 약 0.13 억 번
- 두 번째 3 x 3 Conv (핵심): 3 x 3 x 64 x 64 x 28 x 28 약 0.29 억 번 (채널이 줄어서 확 싸짐!)
- 세 번째 1 x 1 Conv (확장): 1 x 1 x 64 x 256 x 28 x 28 약 0.13 억 번
- 총합: 약 0.55억 번 연산
AlexNet, VGG, ResNet 실습코드
AlexNet VGG ResNet (파이썬을 통해 직접구현) 모델훈련을해보고 사용해보는 예시가 있다.
https://github.com/ohmanbo/AIFFEL_study/blob/main/CV/ch08.ipynb
https://github.com/ohmanbo/AIFFEL_study/blob/main/CV/ch08.ipynb