
약 인공지능 / 강 인공지능
AI의 종류
- 규칙기반 AI – 미리 작성된 일련의 규칙이나 알고리즘에 의해 작동되는 AI
- 머신러닝 – 데이터를 통해 모델을 학습시키고, 학습시킨 모델로 예측(Regression)이나 분류(Classification)를 수행. 데이터의 양과 품질이 모델 성능에 중요한 영향을 미침. 주로 이미지 및 음성 인식, 자연어 처리, 데이터 기반 예측.
- 딥러닝 – 인공 신경망을 활용하여 정보를 처리하고 전송하는 방식을 시뮬레이션 하도록 설계된 알고리즘. 주로 이미지 및 음성 인식, 자연어 처리, 자율적 의사결정 등이 있다.
딥러닝의 계층
- 입력층 (Input Layer): 현실에서 데이터 축적 > 데이터 불러오기 > 데이터 전처리
- 은닉층 (Hidden Layer):
- 출력층 (Output Layer): 모델이 예측한 결과를 보는순간
모델 학습방법
지도학습(Supervised Learning) – 문제과 답(Label)을 알려주고, 유사성을 알아서 파악하라고(훈련) 한뒤 또 다른 문제를 주고 답을 예측하게하는것
- 회귀(Regression) – 추세를 예측하는것. 그래프에있는 추세선을 Regression Line 이라고 함.
- 분류(Classification) – 말 그대로 분류하는것.
비지도학습(Unsupervised Learning) – 문제만 주고 답을 알아서 찾으라는 형태.
- Clustering – 입력 데이터를 기준으로 비슷한 특징을 가진 데이터끼리 군집(Cluster)로 나누는 알고리즘. (=그룹화)
- Dimension Reduction – 주요값을 분류하고 불필요한 정보 삭제
준지도학습(Semi-Supervised Learning) – 학습데이터에 답이 있는것도 있고 없는것도 상당히 많이 존재할때 사용
- 예시: 수만 장의 흉부 X-ray 사진이 있을 때, 의사가 일일이 “이건 폐렴, 이건 정상”이라고 적어주는 데는 엄청난 시간과 비용이 듭니다.
- 이때 의사가 라벨링한 소량의 데이터와 라벨링되지 않은 대량의 데이터를 함께 학습시키면, 적은 비용으로도 지도학습에 가까운 성능을 낼 수 있습니다.
강화학습(Reinforcement Learning) – 문제를 주고 먼저 풀게한뒤 잘했는지 못했는지 feedback 와 reward를 주면 이 feedback과 reward를 통해 학습 함.
클러스터링(Clustering)
- K-means: K개의 mean(평균, 중심) 값을 입력해서 K 갯수 만큼 분류하는 알로리즘. 어떤 중심점과 가까운지를 기준으로 클러스터링하다보니 복잡한 형태에서는 원하는 형태로 그룹화가 되지 않을수도있다.
- DBSCAN (밀도 기반 군집화) – 데이터가 많이 몰려있는 부분을 선 고려하여 그룹화 시킴. 구체적으로 보면 임의의 점 P(Sample)을 기준으로 특정거리 (Epsilon) 내에 점이 M(Min samples) 개 이상이 있다면 하나의 군집으로 간주. 같은 클러스터내의 점P들을 e-이웃(Epsilon-neighborhood)라고 부르며 같은 cluster 안에 이웃이 M개 이상이면 핵심 샘플 or 핵심 지점 이라 부른다.

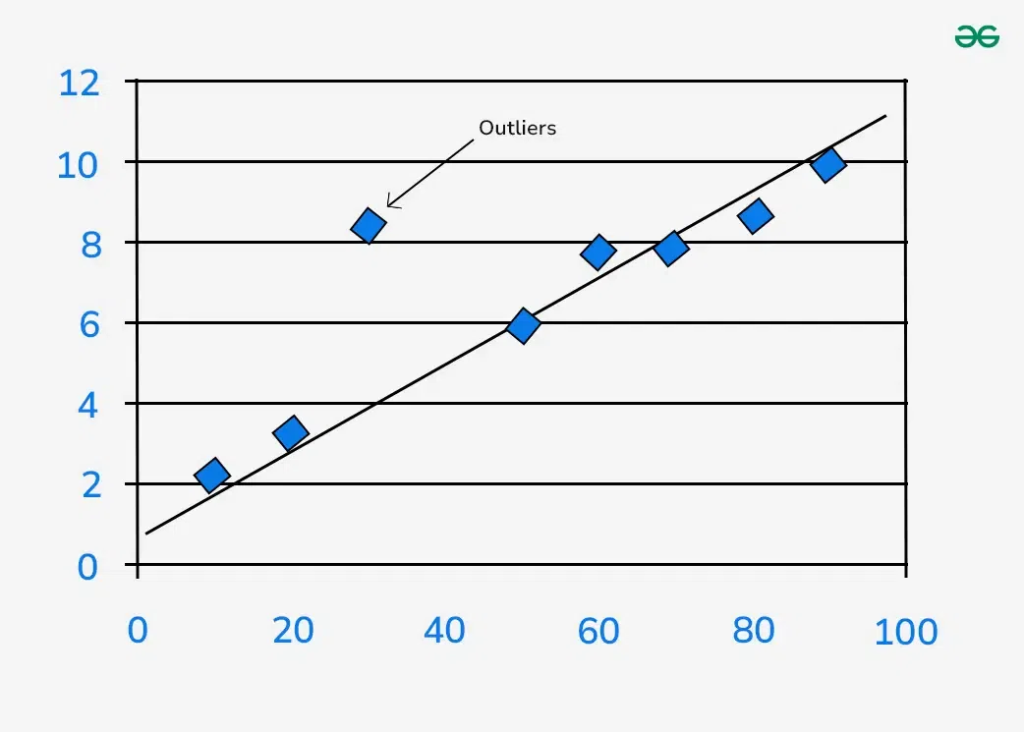
Outlier Detection (이상치 탐지): 데이터가 일반적인 군집과는 너무 멀리 많이 떨어져서 고립되어있는경우 이를 이상치(outlier)라고 부른다.
Dimensional Reduction (차원 축소): 고차원 데이터를 저차원인 새로운 데이터로 변환하는것.
Discrete (이산형): 하나씩 셀 수 있는 형태
현실에서 사용되는 Transformer의 Decoder 기반 모델
Transformer를 공장으로 보면 Encoder와 Decoder는 공장안에있는 기계라고 보면 됨. Transformer는 이 기계들을 잘 조합하여 만든 전체 신경망 아키텍쳐.
- Transformer: 데이터 간의 관계를 한꺼번에 파악하는 어텐션(Attention) 매커니즘을 핵심으로 하는 신경망 구조
- Encoder: 입력된 문장 전체를 읽고 그 의미와 문맥을 수치화된 정보(Vector)로 응축하는 [이해 도구]
- Decoder: 인코더가 만든 정보나 이미 생성했던 단어들을 바탕으로, 다음에 올 가장 적절한 단어를 하나씩 예측해 내뱉는 [생성 도구]
- etc 도구: Transformer에는 Positional Encoding, Feed-Forward Network (FFN), Residual Connectoin, Layer Normalization 등 도구가 더 있다.
Attention Macanism (어텐션 매커니즘): 문장 속 단어끼리의 연관성(가중치)를 계산하는 수학적 원리로 엔진 역할을 중심으로,
Positional Encoding(번호표)로 순서를 정하고, FFN(가공기)로 의미를 분석하고 Residual & Layer Norm(안전장치)로 전체 공정을 안정화 하는 구조로 되어있음.
GPT, LLaMa, PaLM, Gemini, Mistral 등.
언어모델 학습방법
Pre-train (사전학습) – “세상의 상식을 배우는 의무교육”
모델이 아무것도 모르는 상태에서 인터넷에 있는 방대한 데이터를 통째로 읽으면 언어의 규칙과 상식을 배우는 단계.
- 학습데이터: 위키, 뉴스, 블로그, 소스 코드 등 초대형 단어 뭉치 (Raw Text)
- 학습방법: 다음에 올 단어 맞추기 무한 반복
- 결과: 문법을 깨우치고, “지구는 둥글다” 같은 상식을 갖게 되지만, 정작 “내 질문에 친절하게 대답해” 같은 특정 목적은 아직 모르는 상태.
Fine-tuning (미세 조정) – “특정 업무를 배우는 전공 연수”
사전 학습이 끝난 모델을 가져와서 우리가 원하는 목적을위해 추가로 학습시키는 단계.
- 학습데이터: 질문-답변 쌍이나 요약문, 번역문 처럼 사람이 정성스럽게 많은 소량의 고품질 데이터.
- 학습방법: 모델에게 이제부터는 질문이 들어오면 이런식으로 대답해야 해 라고 가이드라인을 준다.
- 결과: 챗봇이 되거나 (ChatGPT), 법률 상담가, 코딩 도우미 등 전문적인 도구로 변신.
RLHF(Reinforcement Learning from Human Feedback) – 사람의 피드백으로 강화 학습
ChatGPT를 완성시킨 가장 핵심이 되는 기법
RLHF가 필요한 이유?
- 사전 학습이 끝난 모델은 지식은 많지만, 유해한 답변을 내놓을 수 있음.
- 세상에 모든 질문에 정답을 만드는것을 불가능.
- 인간의 판단(Feedback)을 수식화 하여 모델에게 전달하는 방법으로 해결
ChatGPT의 보상 모델 활용 방법
- 작동 원리: 모델이 질문 하나에 4~5개의 답변을 생성 후, Ranking을 정함.
- 학습: 이 순서 데이터를 바탕으로 보상 모델 학습 시킴. 보상 모델은 인간이라면 이 답변에 몇접을 줄것인지 예측하는 인간대역.
- 효과: 사람은 상당히 적은수의 샘플에만 순위를 매기면 됩니다. 보상 모델이 완성되면, 이후에는 수억개의 데이터에 대해 인간 대신 자동으로 보상을 계산해줍니다.
- 스스로 학습: 이제 역으로 모델이 보상모델을 상대로 연습게임을 하면서 고득점을 획득하기위한 방법을 연구하면서, 가중치를 개선합니다.
Machine Learning Architecture Process (머신러닝 아키텍쳐)
머신러닝은 아래의 플로우 차트 가집니다. 설명은 차트 아래에.
graph LR
%% 1단계: 데이터 준비
subgraph Step1 ["데이터 준비"]
direction TB
A1[데이터 수집] --> A2[데이터 정제]
A2 --> A3[데이터 레이블링]
A3 --> A4[데이터 분석 및 시각화]
end
%% 2단계: 모델링
subgraph Step2 ["모델링"]
direction TB
B1[피쳐 엔지니어링] --> B2[모델 설계]
B2 --> B3[모델 학습]
end
%% 3단계: 모델 평가
subgraph Step3 ["모델 평가"]
direction TB
C1[모델 검증] --> C2[성능 개선]
end
%% 4단계: 모델 배포
subgraph Step4 ["모델 배포"]
direction TB
D1[배치 인퍼런스] --> D2[온라인 인퍼런스]
D2 --> D3[엣지 인퍼런스]
end
%% 단계 간 가로 연결
Step1 --> Step2
Step2 --> Step3
Step3 --> Step4- 데이터 준비: 학습 시킬 데이터를 만들고 모으는 과정
- 데이터 정제: 데이터 수집을 통해 확보한 데이터는 일관되지 않고 규칙적이지 않을 가능성이 높아 데이터 정제(Data Cleansing) 프로세스를 통해 누락된 데이터를 채우고 불필요한 데이터를 제거함
- 데이터 레이블링: 해당 데이터가 무엇을 뜻하는시 라벨을 달아주고 태그를 달아주는 과정. 이 정보를 통해 모델이 학습하므로 잘못된 정보가 있으면 모델 성능이 크게 떨어지게 된다.
- 데이터 분석 및 시각화: 다양한 값이나 그래프를 통해 이상치 식별, 상관관계 및 편향 분석, 가설 수립 및 변경, 데이터 패턴 확인.
- 피쳐 엔지니어링: 특징 선택, 특징 샘플링, 특징 변환(문자열orObject를 숫자로), 특징추출, 특징구성(기존 특징을 활용해 새로운 특징을 생성하는 과정 예: 지출종류가 여러가지있으면 총 지출이라는 특징을 만들어줄수있다)
- 모델 설계:
MLOps
flowchart TD
%% 외부 컴포넌트 정의
Repo[코드 저장소]
Lake[데이터 레이크]
Monitor[모니터링]
Feature[피쳐 스토어]
Analysis[데이터 분석]
%% 7번 조건을 위한 투명한 중간 기착지 (Junction)
J(( ))
style J fill:transparent,stroke:transparent,color:transparent
%% 중앙 ML 파이프라인 그룹 (세로 정렬)
subgraph Pipeline [ML 파이프라인]
direction TB
D1[데이터 준비] --> D2[모델링] --> D3[모델 평가] --> D4[모델 배포]
end
%% 1. 상단: 코드 저장소 <-> 그룹
Repo <--> Pipeline
%% 2. 좌측: 데이터 레이크 -> (중간 지점) -> 그룹
Lake --> Pipeline
%% 3. 우측: 그룹 <-> 모니터링
Pipeline --> Monitor
%% 4. 하단: 그룹 <-> 피쳐 스토어
Pipeline <--> Feature
%% 5. 모니터링 -> 데이터 분석
Monitor --> Analysis
%% 6. 피쳐 스토어 -> 데이터 분석
Feature --> Analysis
%% 7. 데이터 분석 아래쪽 -> 2번 화살표 중간(J)으로 연결
Analysis --> Lake