
트랜스포머는 왜 좋은가?
- 병렬처리
- 모든 시퀀스를 한번에 처리
Self-Attention Layer
- 하나의 정보를 처리할 때 input sequence의 다른 정보들의 영향력을 계산
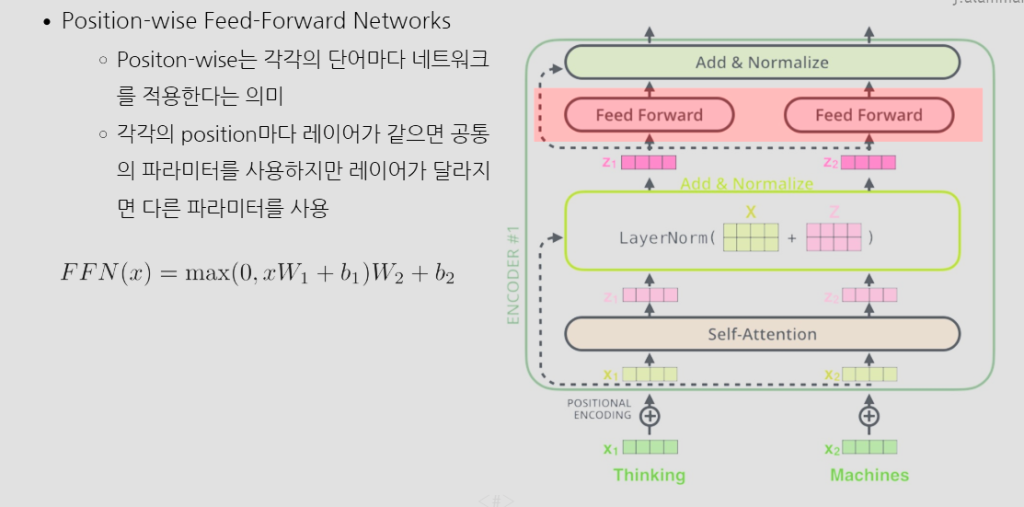
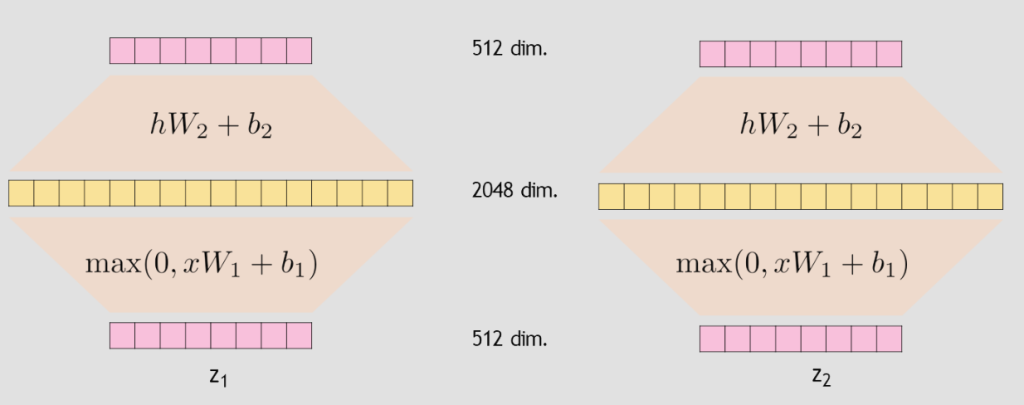
Feed Forward Neural Network
모델의 비선형성 추가

Input Embedding
- Input -> embedding algorithm -> 토큰 벡터화
Positional Encoding
- 추론시 필요한 순서정보를 보존하기 위해 (번역, 생성, 문맥 이해 등에 필요)
- 병렬처리를 가능하게함.
- RNN은 토큰을 하나씩 입력하지만 Transformer는 한번에 모든 단어를 처리
- 위치 정보를 보존해야 할 필요성이 있다.
- Sin & Cos 사용하는 이유
- 같은 위치 정보에 해당하는 위치 벡터 값이 같아야 한다. (주기성)
- 위치 벡터의 값이 너무 커지면 안된다. (-1 ~ 1)
Self-Attention
- 하나의 정보를 처리할 때 input sequence의 다른 정보들의 영향력을 계산 -> Dependency가 존재한다.
- Feed Forward Network에는 dependency가 존재하지 않는다.

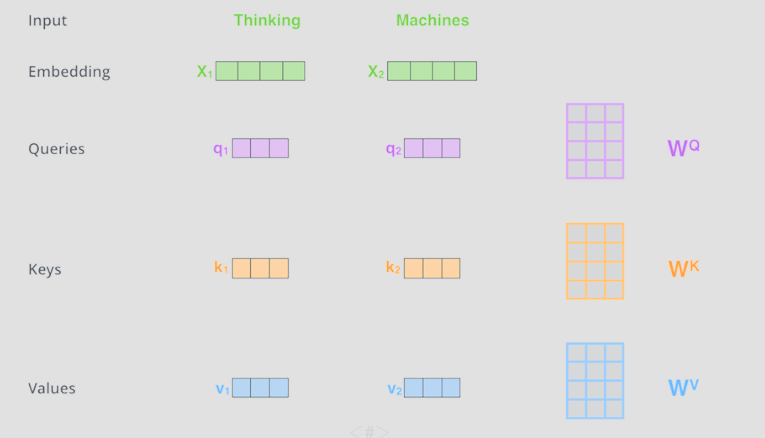
Q, K, V
- 3개의 vector 생성 -> Encoder의 input vector
- Query : 현재 단어의 표현, “나는 지금 무엇을 찾고 있나?”
- Key : 각 토큰이 “나는 이런 특징으로 검색될 수 있다”고 내놓는 검색용 특징
- Value : 실제 단어의 표현 즉 실제 값, “쿼리와 키를 비교해서 나온 score”
Value 벡터가 softmax 결과값과 곱해져서 Attention 벡터가됨
원래 임베딩 테이블에는 “tower”라는 단어 하나에 벡터 하나만 있어. 이건 “타워”의 평균적인 의미라서, 건축물인지 중장비인지 구분되지 않아.
임베딩 테이블의 "tower":
[0.5, -0.2, 0.8, ...] ← 어떤 tower인지 모름Self-Attention을 거치면 같은 “tower”라도 주변 단어에 따라 다른 벡터가 돼.
"Eiffel tower"에서의 tower:
α(Eiffel)=0.7, α(tower)=0.3
→ 새 벡터 = 0.7·V(Eiffel) + 0.3·V(tower)
→ 건축물/파리/높음 의미 쪽으로 이동
"crane tower"에서의 tower:
α(crane)=0.7, α(tower)=0.3
→ 새 벡터 = 0.7·V(crane) + 0.3·V(tower)
→ 중장비/건설/금속 의미 쪽으로 이동Self Attention 재 정리
Step 1: q, k, v 생성
Residual Connection
Layer Normalization