
이 글은 Stanford CME295 Transformers & LLMs 클래스 유튜브영상을 보고 요약한 내용입니다.
https://www.youtube.com/watch?v=Ub3GoFaUcdsTransformer의 등장 배경, 특징등이 궁금하다면 이전 글을 참조해주세요.
1. 강의 소개
강의 목표
- Transformer가 어떻게 작동하고, LLM과 어떤 연관성이 있는지 이해하기.
- LLMs 이 어떻게 훈련되고 어떤 다양한 용도로 사용되는지 배운다.
강의 대상
- 머신러닝 기본을 이해 하는 자
- 선형 대수학을 이해 하는 자
- LLM에 관심있는 자
Textbook
강의 링크
치트 시트
출처: https://github.com/afshinea/stanford-cme-295-transformers-large-language-models
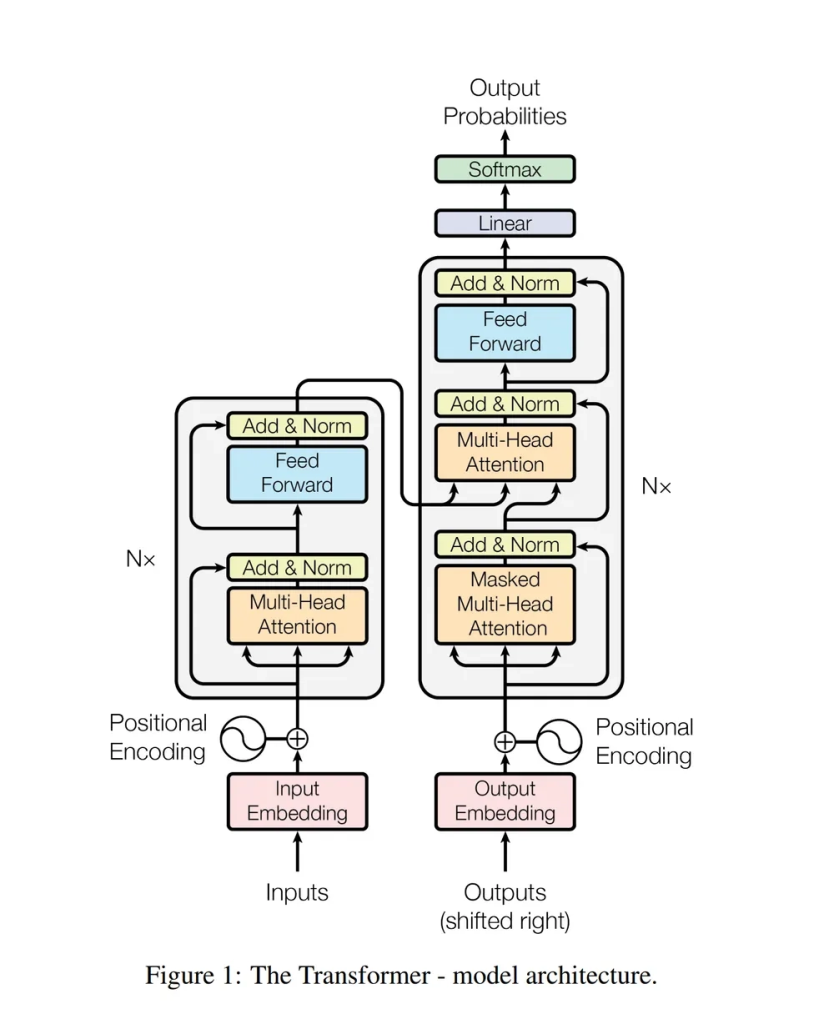
2. NLP tasks overview (자연어 처리 3가지 작업)
Classification (분류)
graph LR;
A(Input Text) --> B[Model];
B --> C(3);- Sentiment extraction (감정 추출): 스토리를 읽고, 슬픈지 기쁜지 등 감정을 추출함.
- Intent detection(목적 감지): 프롬프트가 “6시에 알람 맞춰줘” 라면 알람을 설정하는게 목적인것을 파악해냄.
- Language detection(언어 감지): 영어인지 한국어인지 판별.
- Topic modeling
“Multi”-classification (다중분류)
graph LR;
A(Input Text) --> B[Model];
B --> C(3:Input, 5:text);- Part of speech tagging
- Named entity recognition (NER): 장소, 시간, 사물등 알려진 entity를 인식함.
- Dependency parsing
- Constituency parsing
Generation (생성)
graph LR;
A(Input text) --> B[Model];
B --> C(Out text);- 머신 번역 (언어 번역, 영어 -> 한국어)
- 질문에 답변
- 요약
- 텍스트 생성 (소설, code 등)
Sentiment extraction (감정 추출)
graph LR;
A>This teddy bear is SO CUTE!] --> B[Model]
B --> C('+')3. Tokenization (토큰화)
모델은 (컴퓨터는) text를 이해할수없어서 문자를 숫자데이터로 바꿔줘야한다.
A cute teddy bear is reading.
text는 복잡하고 무한이 많은 조합이 가능하기때문에 문장단위로 토큰화하는건 무한히 많은 메모리를 요구하므로 불가능하고 문장을 토큰단위로 쪼개어 컴퓨터가 이해할수 있도록 만들어야한다.
토큰화 방식은 다양 한방법이 존재한다
arbitrary (문법/띄어쓰기)
graph TD; A[A] B[cute] c[teddy bear] d[is] e[reading] f[.]
word (단어)
graph TD; A[A] B[cute] c[teddy] d[bear] e[is] f[reading] g[.]
sub-word (하위 단어)
sub-word 는 하위단어 토큰화방식인데 한마디로 단어뿌리기반으로 분리해서 의미를 word 기반보다 더 작게 쪼개는것입니다.
car 와 cars 라는 단어가 있을때 이 둘은 비슷하지만 다릅니다 car는 a car, the car, your car 이런식으로만 등장이 가능하지만 cars는 a나 the 같은 관사 없이도 사용이 가능합니다.
이걸 분리해주지 않으면, 모델은 이부분을 학습하기가 매우 어려울것입니다. a cars 같은 틀린 문법이 번역 결과로 출력이 될수도 있겠죠.
graph TD; A[A] B[cute] c d[##dy] e[bear] f[is] g[read] h[##ing] i[.]
이 예제에서도 read 와 read+ing인 reading은 전혀 다른의미가 되는데, 이런식으로 분리해주면 모델이 prefix suffix개념도 이해 할수있게 된다.
character-level (자소단위)
자소단위는 오타나, 대소문자 (영어의경우) 오류, 에 강해지는 장점이 있지만, 비현실적인 vocab(단어장) 사이즈에 처리속도가 매우느리고, 자소단위는 의미가없어서 모델이 의미를 이해하는게 거의 불가능하다. 물론 짧고 간단한 문장은 처리가 가능하기도 하지만. 현재 실제로는 쓰이지않는다.
한국어의 subword
한국어도, 띄어쓰기, 단어, 글자, 자소, 하위단어 등 여러기준으로 토큰을 나눌수있고 현재 가장 많이 쓰이는건 “하위단어 기반 토크나이저” 이다.
다시한번 강조하지만 토큰화를 시키는 이유는 메모리 한계 때문이기도 하지만, 의미 단위로 쪼개져야 AI 모델이 토큰을 재조합해 새로운 글을 작성할수 있다.
Word representation (단어 표현)
One hot encoding (OHE)
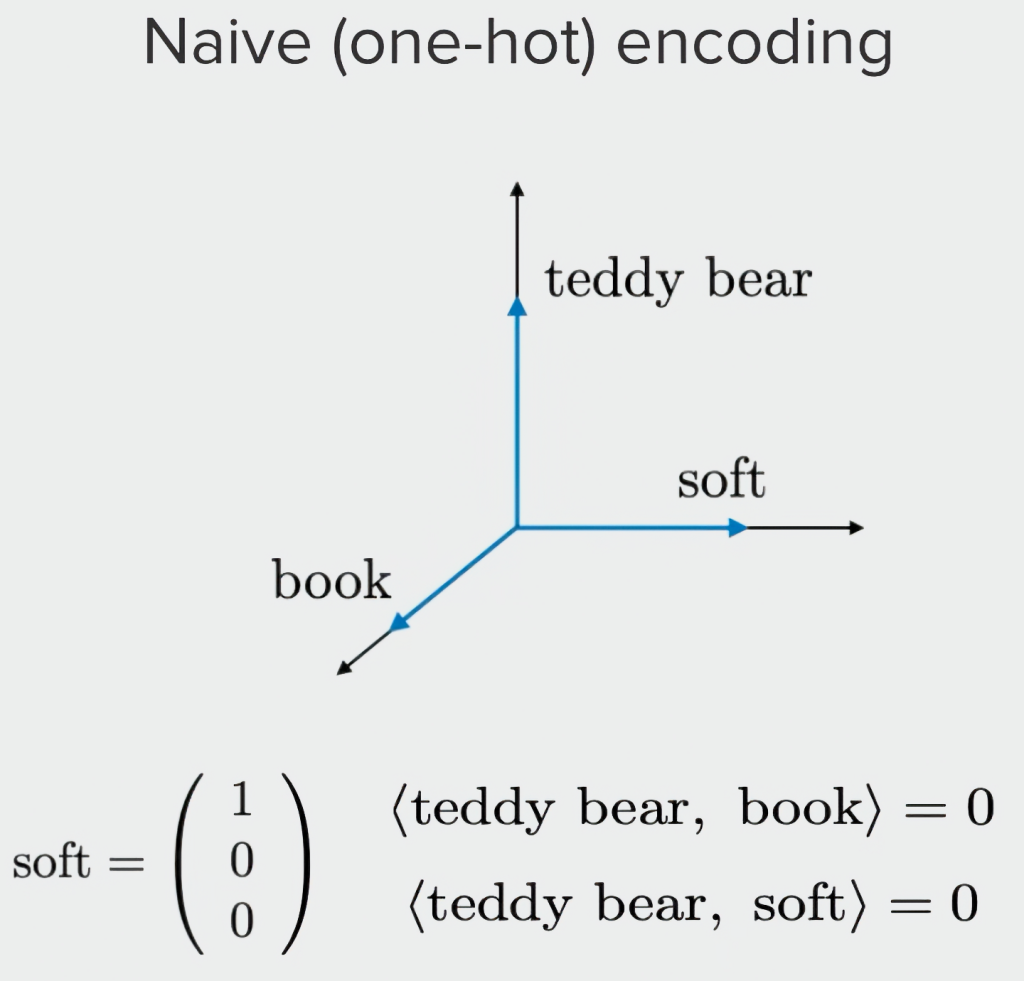
사람들이 주로 쓰는 유사도 측정방식으로는 Cosine Similarity가 존재하는데, 이 방식은 토큰마다 축을 따로만들어야함. 이렇게되면 vocab 수만큼 축이 생기는데, 모든토큰이 다른토큰벡터들로부터 직교를하게되어서 유사도 측정이 불가능함.
사실 이런이유가 아니어도 LLM을만들기 위해서는 무수히 많은 단어를 여러언어로 학습시켜야하는데, 이 방식은 가중치 용량이 너무커져서 사실상 안씀. 못씀.
Embedding 도입
임베딩은 토큰마다 축을 만드는게아님
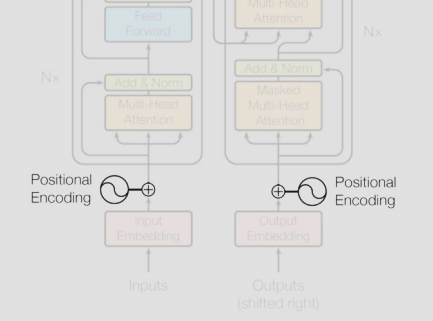
Lecture 2 – Transformer-Based Models & Tricks
https://www.youtube.com/watch?v=yT84Y5zCnaA&list=PLoROMvodv4rOCXd21gf0CF4xr35yINeOy&index=2Transformer 전체 흐름을 정검
아래 플로우 차트에서 왼쪽은 Encoder 오른쪽은 Decoder Component이다.
이 형태가 기본형인 이유는 Transformer가 처음에 머신러닝을 활용한 번역모델로 개발되었기 때문이다.
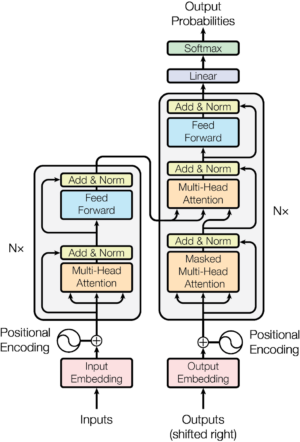
Multi-Head Attention Layer
이곳이 바로 self-attention 매커니즘이 작동하는 위치이다. 이 그림에서 Scaled Dot-Product Attention 부분에서 h의 갯수가 head의 갯수다. 이 갯수만큼 attention 매커니즘을 반복한다.
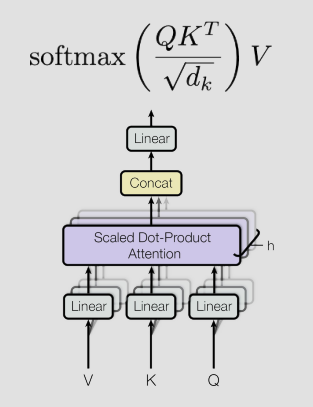
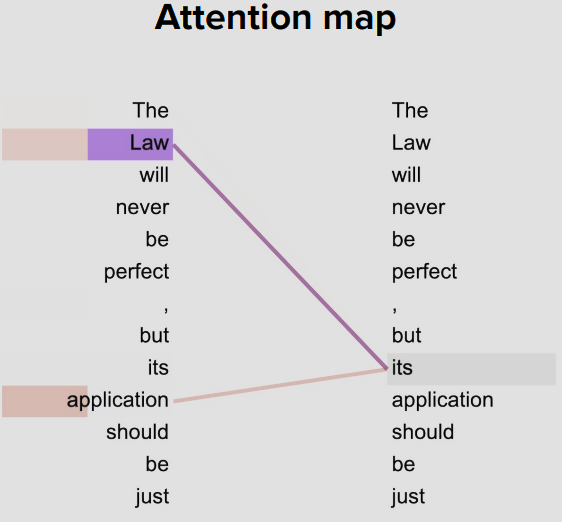
Attention Map
각 토큰(단어, Q)와 K를 내적해서 큰 값 (= 코사인 유사도가 큰값)에 매칭 시켜준다.
이 후 위에있는 softmax 함수처럼 Root dk로 나눠준다. (값이 너무 커지거나 작아지는걸 방지)
스탠포드 교수는 각 header마다 서로다른 시각으로 단어가 무슨 의미를 갖는지 이해 할거라고(may) 한다
Masked vs unmasked 차이 – 미래를 볼 수 있는지 차이

Decoder에서 masked & unmasked 2중으로 처리하는 이유
두 Attention의 역할 분담
이렇게 비유해볼게. 통역사가 한국어로 통역할 때 머릿속에서 두 가지를 동시에 해야 해.
Masked Self-Attention의 역할 — “내가 방금까지 한국어로 뭐라고 말했더라?”
지금까지 만든 한국어 문장의 흐름을 파악하는 거야. “나는 학교에서”까지 말했으면 다음에 동사가 와야 자연스럽다는 걸 한국어 문법 차원에서 판단해. 이건 영어 원문과는 무관한, 출력 언어 자체의 일관성을 챙기는 단계.
Encoder-Decoder Attention의 역할 — “그런데 영어 원문은 뭐였지?”
이제 영어 원문을 다시 들여다봐. “school” 다음 위치에 해당하는 의미를 찾아야 한다고 판단하면, 인코더 출력에서 “study” 토큰에 높은 가중치를 줘. 이건 소스 언어와 타겟 언어를 연결하는 단계.

Positional Embeddings
RNN에서는 단어를 순차적으로 처리했지만 트랜스포머는 그렇지 않다. 심지어병렬처리까지 한다.
따라서 임베딩된 토큰에 해당 토큰의 위치정보를 주입시켜주는데 그게 바로 positional embedding 이라고 한다
(위치정보를 가진 임베딩 이라고 이해하면 쉽다.)
Are the position embeddings static? or learned?
스탠포드 학생이 질문했다, 위치 임베딩이 고정되어있냐? 아니면 학습된거냐? 라는 질문이다.
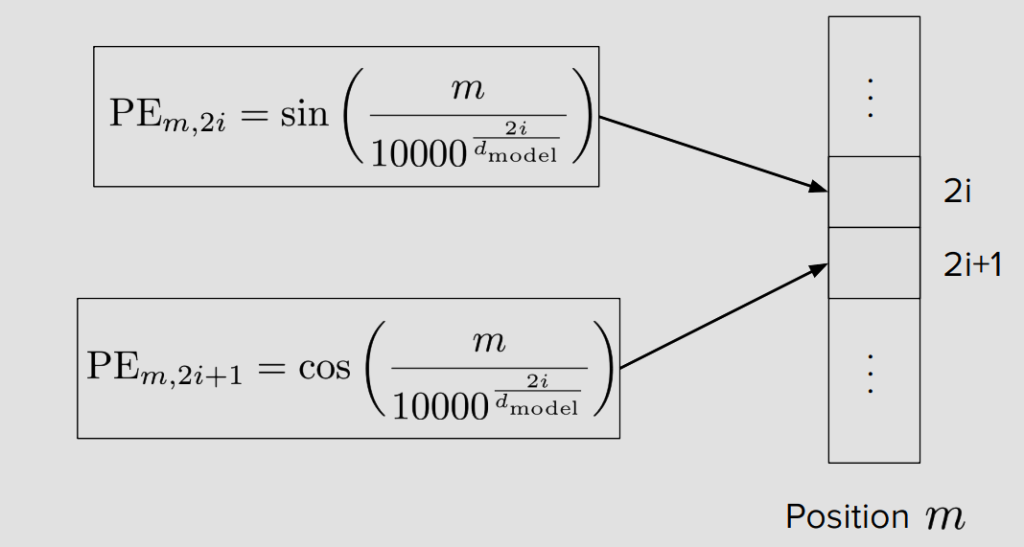
static (고정형) – sin/cos 방식
위치 벡터를 수학 공식으로 미리 계산해서 고정해놓는 방식이야. 우리가 앞서 얘기했던 sin/cos 방식이 바로 이거야.
학습이 시작되기 전에 모든 위치의 벡터값이 이미 결정되어 있어. 학습 과정에서 이 값은 절대 바뀌지 않아. 모델이 만져볼 수 없는 “상수표”야.
PE(pos, 2i) = sin(pos / 10000^(2i/d_model))
PE(pos, 2i+1) = cos(pos / 10000^(2i/d_model))Learned (학습형) — 임베딩 테이블 방식
위치 벡터도 단어 임베딩처럼 학습 가능한 파라미터로 두는 방식이야.
처음에는 랜덤 값으로 시작하고, 학습이 진행되면서 모델이 스스로 “각 위치를 어떻게 표현하는 게 좋을지” 를 데이터로부터 배우는 거야.
position_embedding = nn.Embedding(max_len, d_model)
# 위치 0, 1, 2, ... 마다 d_model 차원 벡터를 랜덤 초기화
# 학습하면서 backprop으로 업데이트됨Answer
고정으로 시작하고, 학습하면서 수정되니까 둘 다임.
Hardcoded Position Embeddings
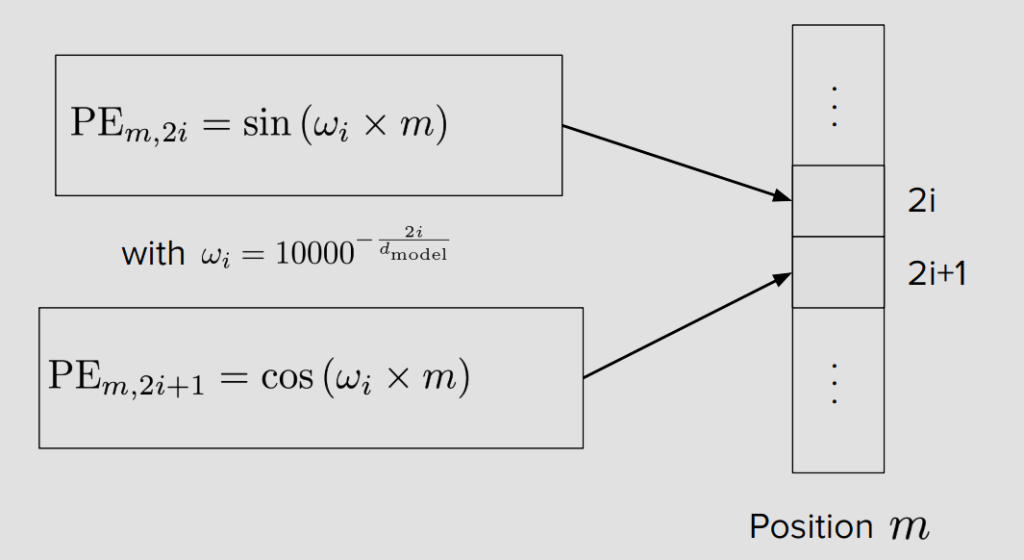
임베딩에 더해야 하므로, Position m 벡터는 d차원의 크기를 가지고있음.
벡터의 각 인덱스는 위에 해당하는 방정식을 사용해서 계산된다.
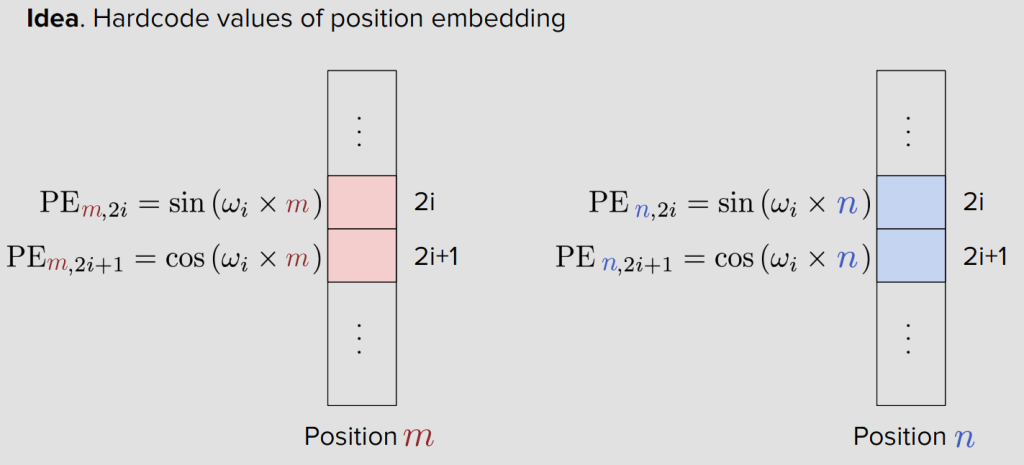
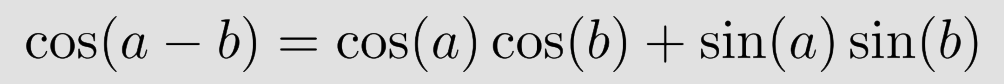
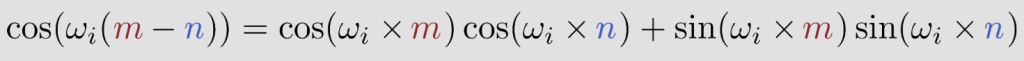
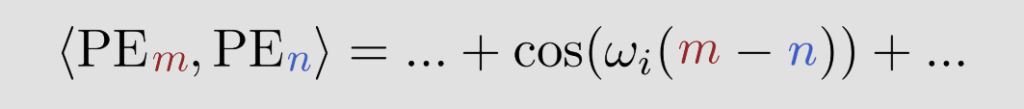
m과 n 사이의 상대 거리에 대한 함수인 코사인 값들의 합.
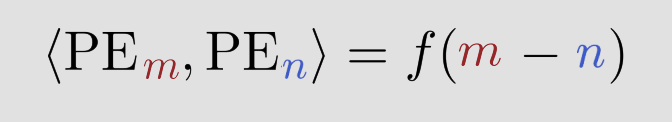
= m과 n의 상대거리 함수
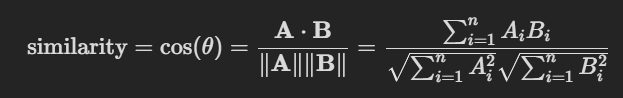
코사인 유사도 = 내적 / normalized 된 각 embeddings
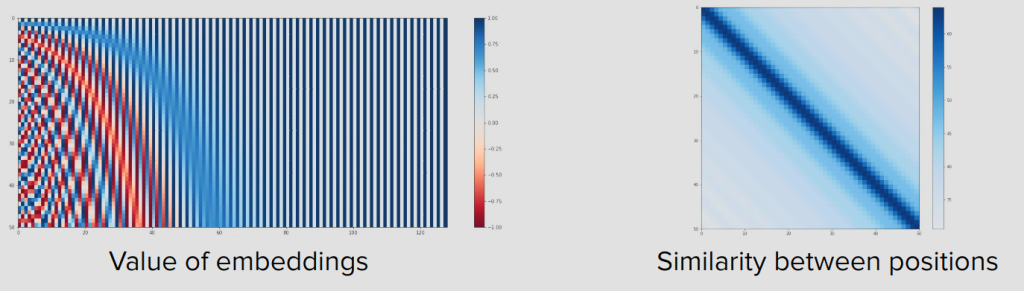

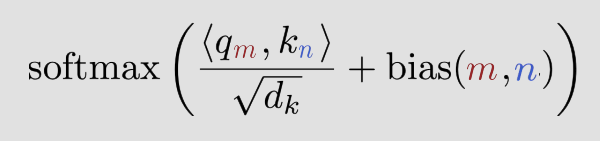
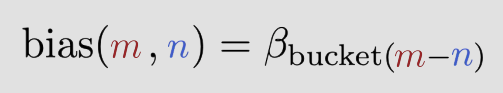
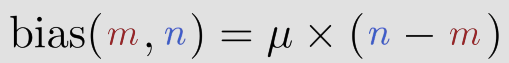
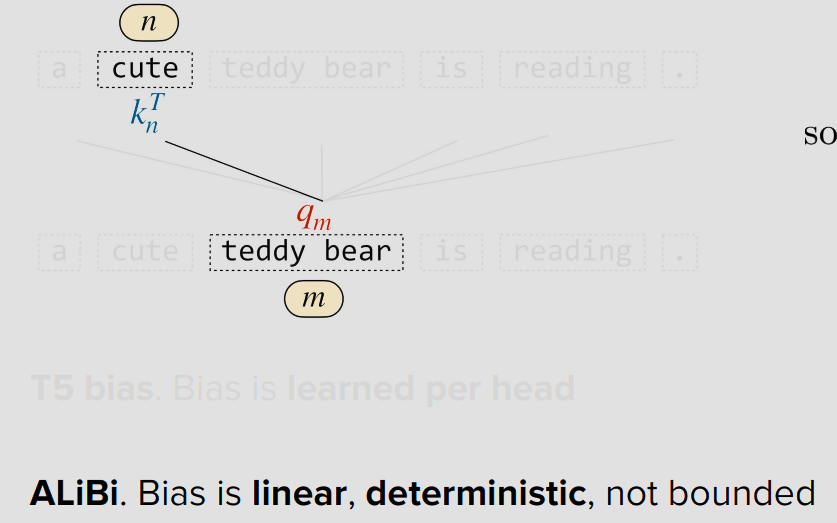
RoPE (Rotary Positional Embedding)
핵심 아이디어: 회전 행렬을 사용하여 Q, V 벡터를 회전시킴
기존 PE는 위치 정보를 임베딩에 더했어. RoPE는 다르게 접근해 — 벡터를 회전시켜서 위치를 표현해.


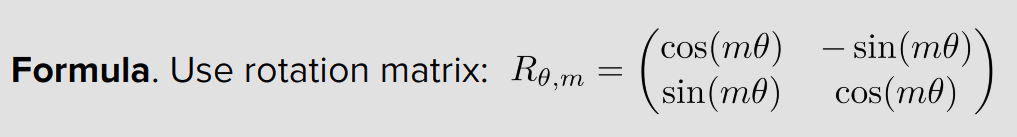
작동 방식 — 어디에 적용되나?
기존 PE는 입력 임베딩 단계에서 한 번 더해지고 끝이야. RoPE는 다른 곳에 적용돼.
RoPE는 Attention 계산 직전, Q와 K에만 회전을 적용
V에는 적용 안 함위치 m에 있는 Q와 위치 n에 있는 K가 있을 때, Q를 m각도만큼, K를 n각도만큼 회전시켜. 그 다음 내적(Q·Kᵀ)을 하면, 신기하게도 결과값이 두 위치의 차이 (m-n)에만 의존하는 형태가 돼.
이게 RoPE의 진짜 마법이야. 절대 위치를 인코딩했는데도 내적 결과는 상대 위치만 반영하는 거야.
벡터를 회전행렬로 회전시키지 않아도 두 벡터의 상대좌표는 구할 수 있지 않니?
네 의문이 맞아 — 좌표만 빼면 거리는 그냥 구해져
그냥 두 토큰의 위치 인덱스(예: pos_q=3, pos_k=5)를 빼면 거리가 나와. 그 자체로는 회전이 필요 없지.
그럼 왜 회전을 쓰냐?
답은 — RoPE의 목표가 단순히 “거리를 구하는 것”이 아니라 **”Attention 점수에 거리 정보가 자동으로 녹아들게 하는 것”**이기 때문이야.
핵심: Attention은 내적(Q·K)으로 작동한다는 점이 결정적
Transformer가 이미 정해놓은 연산 흐름이 있어.
score = Q · K (두 벡터의 내적)이 연산은 절대 안 바꿔. Attention의 본질이니까. 그래서 위치 정보를 이 내적 결과 안에 어떻게든 녹여 넣어야 해.
여기서 두 가지 선택지가 생겨.
선택지 A — Attention 외부에서 거리를 따로 계산해서 score에 더하기
score = Q · K + f(pos_q - pos_k)이게 실제로 존재하는 방식이고, 이름이 있어. “상대 위치 편향(relative position bias)” 또는 ALiBi 같은 방법들이야. 네가 말한 “그냥 좌표 빼서 쓰면 되잖아”가 정확히 이 방식이야.
선택지 B — Q와 K 자체를 회전시켜서, 내적 결과에 거리가 자동으로 들어가게 하기
이게 RoPE야.
그럼 왜 굳이 B(RoPE)를 택했나?
회전이 가진 수학적으로 아름다운 성질 때문이야. 회전 행렬의 특성상,
(R_m · Q) · (R_n · K) = Q · R_(n-m) · K위치 m으로 회전된 Q와 위치 n으로 회전된 K를 내적하면, 결과가 자동으로 (n-m), 즉 상대 위치만의 함수가 돼. 절대 위치 m, n은 사라지고 차이만 남아.
이게 가능한 이유는 회전 행렬이 직교 행렬이라는 특별한 성질을 가지기 때문이야. 더하기로는 이런 성질이 안 나와.
A방식 (편향 더하기) vs B방식 (RoPE)
| 방식 | 어떻게 | 장단점 |
|---|---|---|
| 선택지 A (편향 더하기) | score 계산 후 f(pos_q-pos_k) 추가 | 구현 단순, 하지만 추가 연산 필요 |
| 선택지 B (RoPE) | Q, K를 회전시켜 내적 | 추가 연산 없이 거리 정보 자동 반영 |
RoPE 방식이 추가 연산이 필요 없는 이유? (증명)
Step 1 — 회전이 정확히 무슨 일을 하는지
위치 m에 있는 Q를 회전한다는 건 이런 뜻이야.
원래 Q = [a, b] (2D 예시)
회전된 Q = R(mθ) · Q
= [a·cos(mθ) - b·sin(mθ), a·sin(mθ) + b·cos(mθ)]여기서 R(mθ)는 각도 mθ만큼 돌리는 회전 행렬이야. 위치 m이 클수록 더 많이 돌아가.
K도 마찬가지로 위치 n에서 R(nθ)만큼 회전돼.
Step 2 — 마법이 일어나는 지점: 내적
이제 회전된 Q와 K를 내적해봐.
회전된 Q · 회전된 K
= (R(mθ)·Q) · (R(nθ)·K)여기서 회전 행렬의 수학적 특성이 발동해. 회전 행렬은 직교 행렬이라 다음이 성립해.
R(mθ)ᵀ · R(nθ) = R((n-m)θ)Layer normalization
LN은 한마디로 Vector의 각 component (인덱스 값) 들을 임의의 값으로 정규화 시키는것. (예: -1.0 ~ 1.0 )

벡터에서 계산된 평균값을 뺴주고 standard deviation으로 normalize 시킨다.
감마: re-scailing factor
베타: (앞으로 배울것 -_-)
Post-Norm
2017년 트랜스포머 기본형태
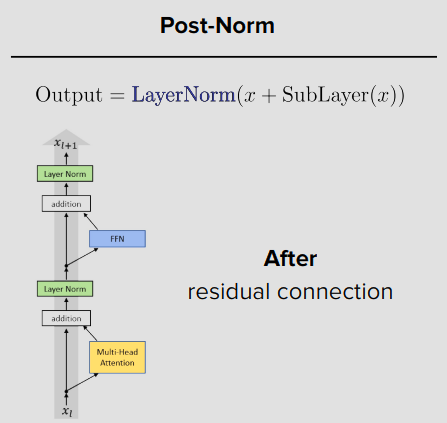
Pre-Norm
요즘 사용하는 방식, Layer Norm이 실행되는 위치가 다름.

Pre-Norm + RMSNorm
완전 최근 사용하는방식은 RMSNorm을 섞여주는건데, 기본적으로 빠름.

Attention approximation
기본적으로 Self-Attention 과정은 각각의 토큰이 다른 모든토큰과 상호작용을 하게 되어있습니다. 그러니까 입력된 문장에 토큰이 10개면 10의 제곱인 100번의 상호작용이 일어나고 토큰이 100개면 1만번의 상호작용이 일어납니다. 입력된 문장이 길면 길수록 연산량이 엄청나게 커집니다.
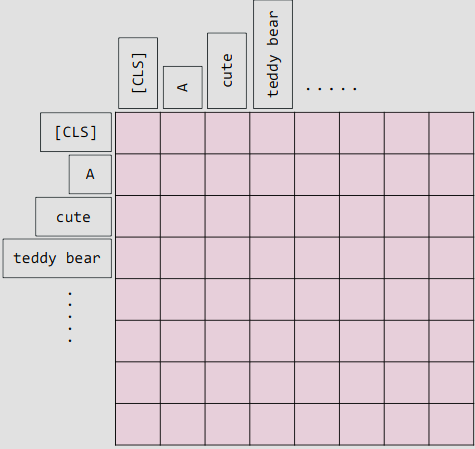
2020년에 Longformer라는 논문이 발표되었는데, 토큰이 모든토큰과 상호 작용하는대신 창문을 제어하여 이웃들하고만 상호작용하도록 효율을 높힌 방식이다.
(아래 사진에서는 흰색부분이 연산에서 제외된것으로 보면 됨.)
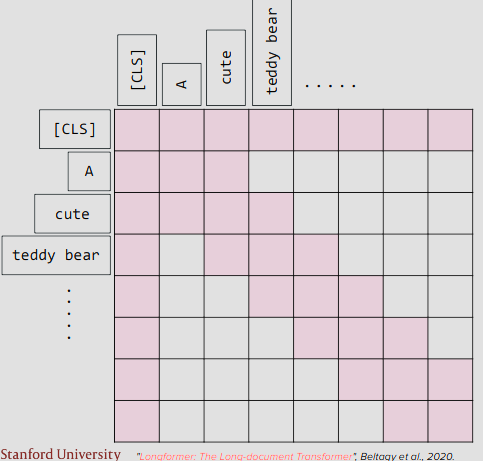
Leveraging local and global attention
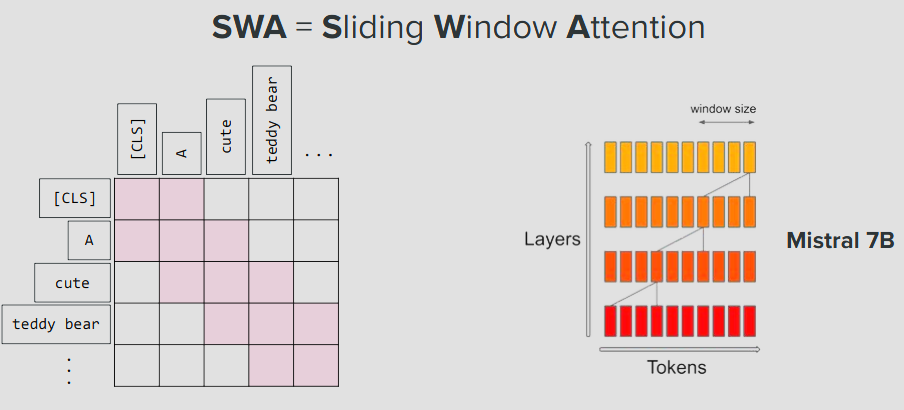
SWA = Sliding Window Attention
최신에는 일부 layer는 global attention을 적용하고 나머지는 local attention을 적용하는 추세인데, 다양한 조합을 시도하고있음.
그리고 이미지에서는 윈도우가 5×5로 매우 작지만 실제로 local attention window를 이렇게 작게 쪼개는건아니고 수천x수천 단위로 엄청큼. 수만x수만 or 수십만x수십만 을 수천단위로 줄이는것임.
CV과정을 공부할떄 convulution 벡터 layer가 보고있는 일부인 receptive field와 같은개념이라고 보면 이해하기 쉬움.
Sharing attention heads
head마다 각각의 projection matrix를 갖지않고 몇개의 축소된 행렬들을 공유하는개념
variation A: full attention 대신 그때 그때 local attention을 사용하는것
variation B: (행렬) orthogonal to all of this heads
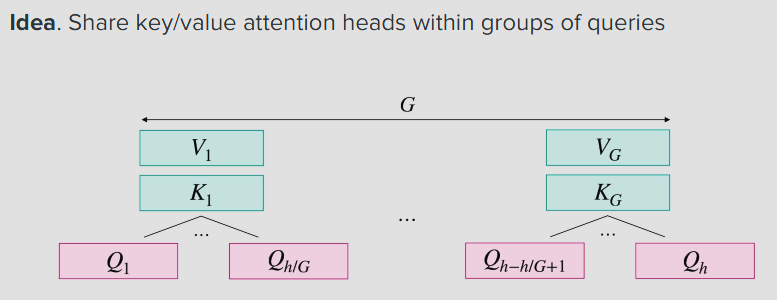
왜 Projection matrix를 share하는데 V K만 쉐어하고 Q는 쉐어하지않을까?
KV cache : saves values of K and V.
KV cache가있는데 이게 너무 커지지않도록하기위해 필요한 알고리즘.
Sharing Matrcies to share
아래 그림에서 G는 Group의 수
MQA
하나의 projection 행렬을 모든 head에 적용

GQA
그룹을 나눠 각각 그룹에맞는 projection 행렬을 적용.

MHA
각 Head가 Query projection, key projection, and value projection 이 존재하는 standard방식.

3가지 케이스를보면 GQA가 가장 좋아보이지만, GQA가 모든 모델에 사용되는건 아니다. 라는것 기억하고 넘어가기 다른것도 필요하니까.
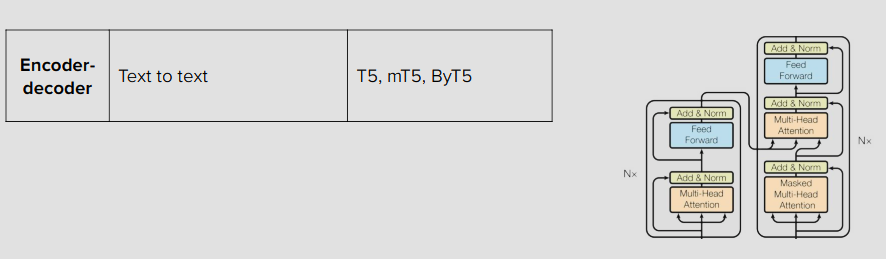
Transformer-based models
Encoder-decoder 모델
T5 = Transformer의 like 바닐라 모델 (text to text)
mT5 (m=multilingual) =
ByT5 (By=Byte) = 바이트레벨 토크나이저 사용으로 사전크기가 작아짐.
sentinel tokens in T5 family = a span of corrupted tokens
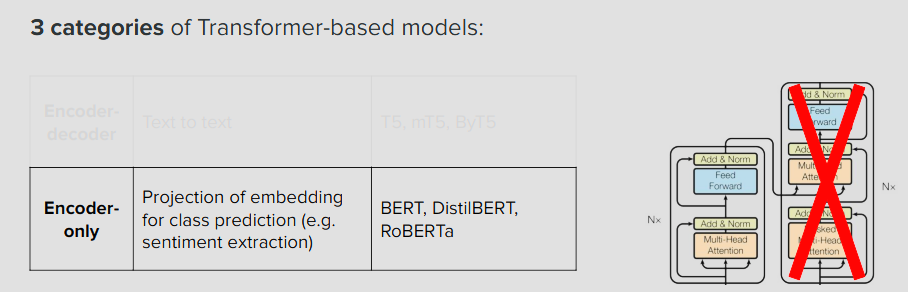
Encoder-Only
decoder가 없어서 분류용으로 사용됨.



왜 요즘 모델은 Decoder-only인데 번역을 잘하지?
첫째, 번역도 결국 “다음 토큰 예측” 문제로 환원될 수 있어. Decoder-only 모델한테 "Translate to Korean: Hello world →" 같은 입력을 주면, 그 다음에 자연스럽게 올 토큰은 “안녕”이지. 즉 번역이라는 별도의 작업이 아니라, 조건부로 다음 토큰을 예측하는 일반 문제의 특수한 경우가 되는 거야. 이게 GPT 계열의 핵심 철학이기도 해 — “모든 NLP 태스크는 결국 다음 토큰 예측”이라는 관점.
둘째, 스케일과 다국어 데이터의 힘이 커. GPT-4, Claude 같은 모델은 인터넷에 있는 어마어마한 양의 다국어 코퍼스 — 번역서, 위키피디아, 자막, 이중언어 웹사이트 등 — 로 학습돼. 데이터와 파라미터가 충분히 커지면, 아키텍처 차이가 만드는 이론적 우위는 점점 줄어들어. “scale은 모든 걸 이긴다”는 격언이 어느 정도 들어맞는 영역이지.
셋째, Instruction tuning과 RLHF가 결정적이야. 사후 학습 단계에서 “사용자 지시를 따르도록” 훈련받기 때문에 “이걸 한국어로 번역해줘” 같은 자연어 명령을 이해하고 수행할 수 있어.
그럼 encoder-decoder는 이제 안 쓰이냐? 그건 아니야. 순수 번역 전문 모델인 Meta의 NLLB, Google의 M2M-100, T5 같은 건 여전히 encoder-decoder를 써. 이론적 장점이 있거든:
- Encoder는 소스 문장을 양방향(bidirectional) 으로 한 번에 처리할 수 있어. “I saw the bank” 같은 문장에서 “bank”의 의미가 뒤에 나오는 단어로 정해질 때, 양방향이 유리해.
- Decoder-only는 인과적(causal) 어텐션 이라 왼쪽에서 오른쪽으로만 봐. 그래서 소스를 읽을 때도 단방향이고, 같은 표현력을 얻으려면 더 많은 파라미터가 필요해.
- 순수 번역 태스크에서는 encoder-decoder가 같은 성능을 더 적은 파라미터로 낼 수 있는 경우가 많아.
정리하자면, 강의의 분류는 “원래 무엇을 위해 설계됐나“에 대한 답이고, 실제로 GPT/Claude가 번역을 잘하는 건 “충분히 크고 잘 학습된 decoder-only 모델은 거의 모든 NLP 태스크를 다음 토큰 예측이라는 하나의 형식으로 풀어낼 수 있다“는 사실 때문이야. 가장 효율적인 구조가 아닐 수는 있어도, 불가능한 건 전혀 아니지. 오히려 단순함과 범용성이라는 큰 장점이 있어서 범용 LLM의 주류가 된 거고.
BERT deep dive